
















































































































































Part 2: Uploading
The National Library of Scotland, Edinburgh Parallel Computing Centre, National Galleries of Scotland and the Digital Preservation Coalition are working together on a project called Cloudy Culture to explore the potential of cloud services to help preserve digital culture. This is one of a number of pilots under the larger EUDAT project, funded through Horizon2020.
We’ve already published a friendly introduction to Cloudy Culture and our second report focuses on uploading data. It will describe in detail how the National Library of Scotland is transferring data into a cloud service provided by Edinburgh Parallel Computing Centre using iRODS data management software (https://irods.org). The use of a web API uploader is also provided by EPCC and compared with iRODS. We want to know how easily, quickly and reliably we can transfer cultural data into the cloud. Is there anything that would dissuade us from using the cloud as a way to help us preserve access to the digital culture the Library is responsible for safeguarding? Can other organisations apply what we’ve learned to the content they’re responsible for?
Within the context of the Cloudy Culture project the remainder of the report will respond to the following questions before arriving at some general conclusions:
- How easy is it to set up an automated process to transfer content into the cloud?
- How often do problems occur that stop the transfer, and can they be removed from future transfers so that reliability improves?
- How long does it take to transfer data and verify that the transfer was successful?
How easy is it to set up an automated process to transfer content into the cloud?
A lot of cloud storage providers allow you to synchronise certain folders on your phone or computer with ease. At the very most you may have to download an app and set up an account. At the very least your important documents are being backed up for you automatically. Apple, Amazon, Microsoft, Oracle, Dropbox and Google offer these services. For the Cloudy Culture project we are using data management software called iRODS to upload most of our content, and in order for us to expose some of the bottlenecks in our iRODS set-up we undertook a small number of tests using a separate web API.
iRODS is a component of a suite of services, including cloud storage, offered to us by our parent project EUDAT and hosted by the Edinburgh Parallel Computing Centre (EPCC). Compared to some of the well-known cloud storage services it is harder to implement. iRODS is well supported on some Linux distributions, but the National Library of Scotland uses Windows. To provide simple access to the Windows network that stores the content we want to upload we set up a dedicated Windows machine running Ubuntu through VMWare Workstation Player. On the Library virtual machine the light(er) weight iCommands component of iRODS was installed and configured to speak with the full iRODS installation at EPCC. 3 firewalls were also modified to increase the security of transfer between the Library and EPCC.
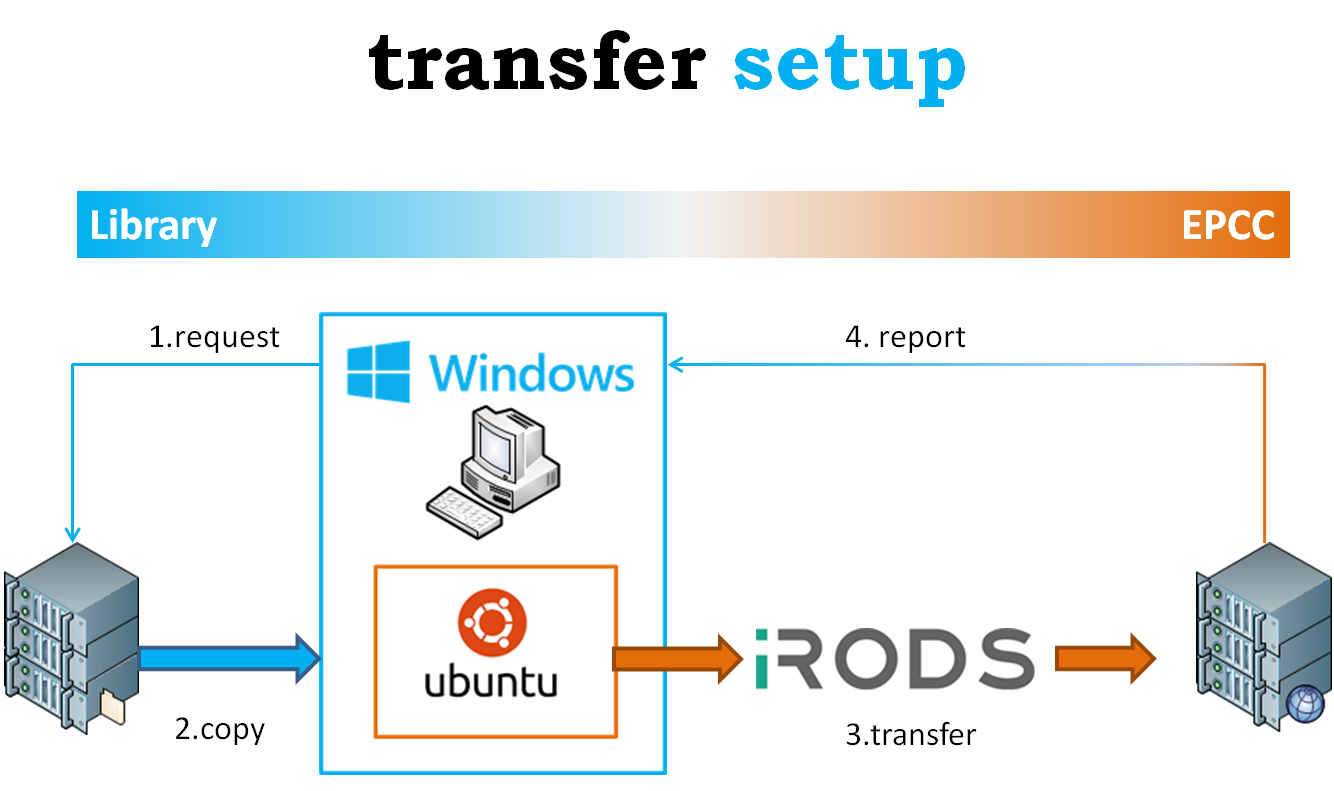
Figure 1. A simplified view of the selection, copy, transfer and report process that the National Library of Scotland uses to transfer content to the EPCC cloud from Windows (Blue) to Linux (Orange) environments.
To prepare for the upload process the Library allocated files to numbered batches, normally totalling 400GB in size, using a database that manages its 20 years of digitised content. A database table was updated to indicate how many batches are to be uploaded in a single session and then the following happens for each batch:
- Request: In Windows a VBA tool operated through a Microsoft Access front end waits for a trigger file to begin requesting the next batch to upload to EPCC.
- Copy: The VBA tool records the time and then calls a Windows executable file written in C++ that copies the files from the Library’s preservation archive to the local Windows machine that runs all of the tools used to transfer files to EPCC. During the copy process and for each file a MD5 checksum is generated and stored in a database for later use and an iRODS command is written into an input report (a text file). The command tells iRODS where the file for upload can be found and which collection (like a folder) the file needs to go within iRODS/EPCC. After copying all of the files to the local Windows PC the VBA tool records the time and generates a trigger file for Ubuntu.
- Transfer: In Ubuntu a bash script is running that looks for a trigger file to say a batch of files is ready to transfer to iRODS/EPCC. The bash script reads the iRODS commands in the input report created by Windows and undertakes a fixity checked upload of each file, creates an iRODS catalogue record, queries the iRODS catalogue record to obtain the MD5 checksum generated by iRODS, and records information into an output report (a text file). The output report includes the filename, MD5 checksum, a transfer success flag, start and end times for the transfer process. Finally a trigger file is created for Windows.
- Report: In Windows the VBA tool looks for a trigger file to say a batch of files has been transferred to iRODS/EPCC. It then analyses the output report to identify any problems during transfer, any differences in the MD5 created during the initial preparation of a batch and the MD5 checksum stored in the iRODs catalogue, and how long the process took. It then repeats the process until all batches have been transferred.
There is a lot of potential to simplify and optimise this workflow but because the project is due to end in June 2017 our approach was to develop the most automation with the least amount of effort and use approaches we were already familiar with.
Towards the end of the upload phase of the project we compared the iRODS service provided by EPCC with a web API upload service provided by them. To reduce our workload we swapped out the Ubuntu bash script for a Python script that allowed us to stage the whole workflow in Windows without having to use a virtual machine. The web API also uses the standard internet port to communicate with the EPCC and not a specific iRODS port so less work is required to open up the firewall. Excluding the reliability and beneficial functionality offered by iRODS (more on this below) setting up the web API was much easier and the workflow has more potential for simplification in the National Library of Scotland’s Windows environment.
How often do problems occur that stop the transfer, and can they be removed from future transfers so that reliability improves?
Of the 92 batches of files, totalling 25TB or 1 million files, that the Library has transferred to EPCC, 1 batch was stopped by a Library power cut, 3 were stopped due to a loss of service at EPCC, and 1 was stopped by a failure of the Library to react to an EPCC notification that the service would be temporarily unavailable. It is conceivable that the Library could use a combination of generators and uninterruptable power supplies (UPS) to continue an unbroken transfer in the event of a power cut but every component between the computer running the transfer tools, the storage locations of the data, and the Library’s connection to the Internet would also need to be running.
In our view the failure rate of 4 in 92 batches is manageable, should be expected, and any transfer schedules will need to incorporate contingency for interruptions. Indeed commercial cloud providers typically define a number of hours down-time per year in their service level agreements.
How long does it take to transfer data and verify that the transfer was successful?
Most batches of files transferred at speeds of 80 to 100 megabits per second (see Figure 2), up to a ceiling of 109Mbps. This is unexpected as the connection all the way between the Library computer transferring the files and EPCC is thought to be at least 1Gbps with the National Library of Scotland and EPCC both having access to the high-speed JANET network.
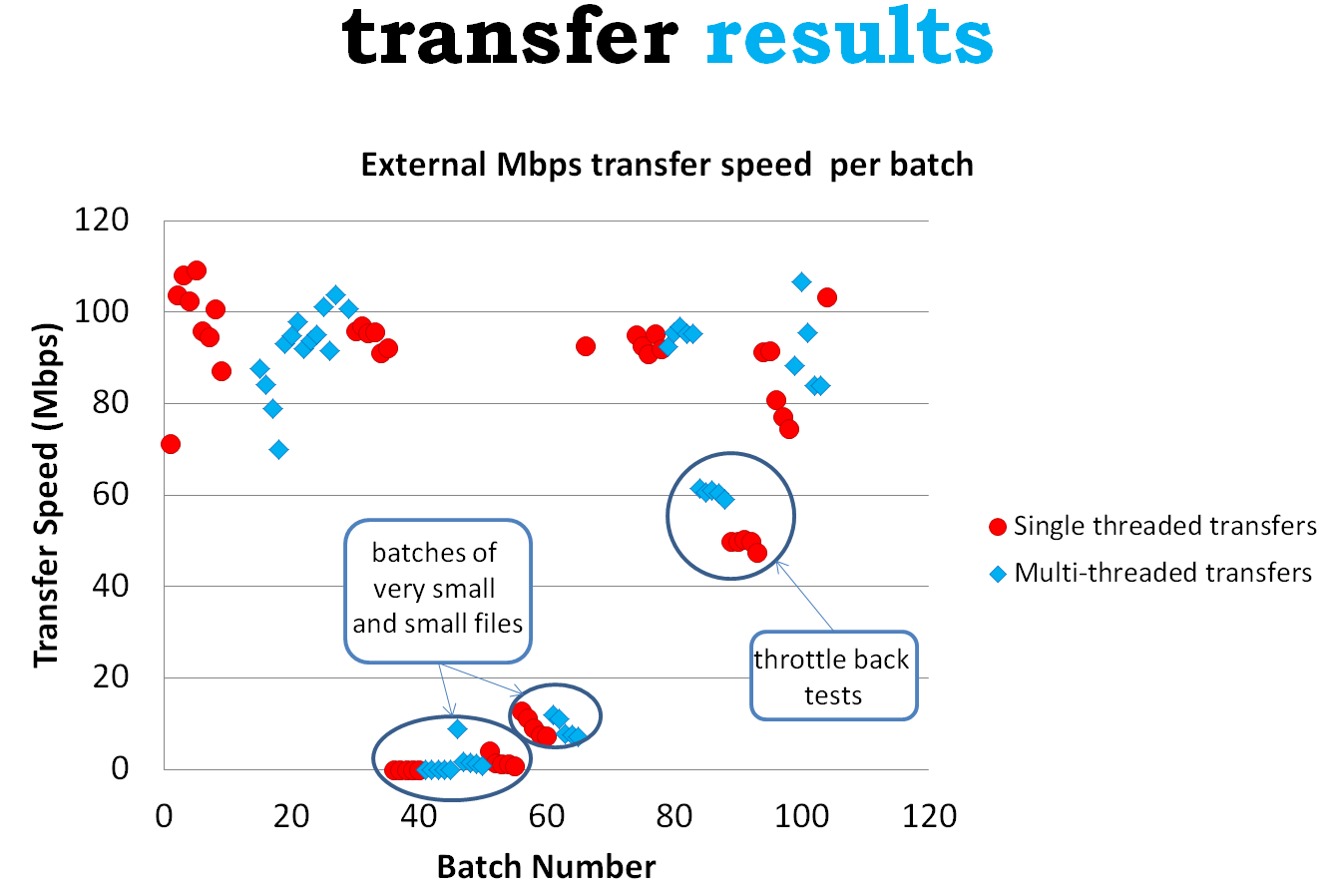
Figure 2: The transfer speed of different batches of files including a comparison between single-threaded and multi-threaded transfers.
Batch transfers simulating the experience of organisations with 100Mbps network or internet connections resulted in transfer speeds of 60Mbps when the iRODS multi-threading option was turned on, and 50Mbps when it was turned off. For the other transfers multi-threading offered no noticeable benefit in our set-up.
Batches containing a lot of small files were up to thousands of times slower than batches with large file sizes. Plotting mean file size in a batch against the Mpbs transfer speed (see Figure 3) suggests a strong relationship between the two, even for a loosely fitting trendline i.e. smaller files in a batch lead to a slower transfer speed and larger files have a faster transfer speed.
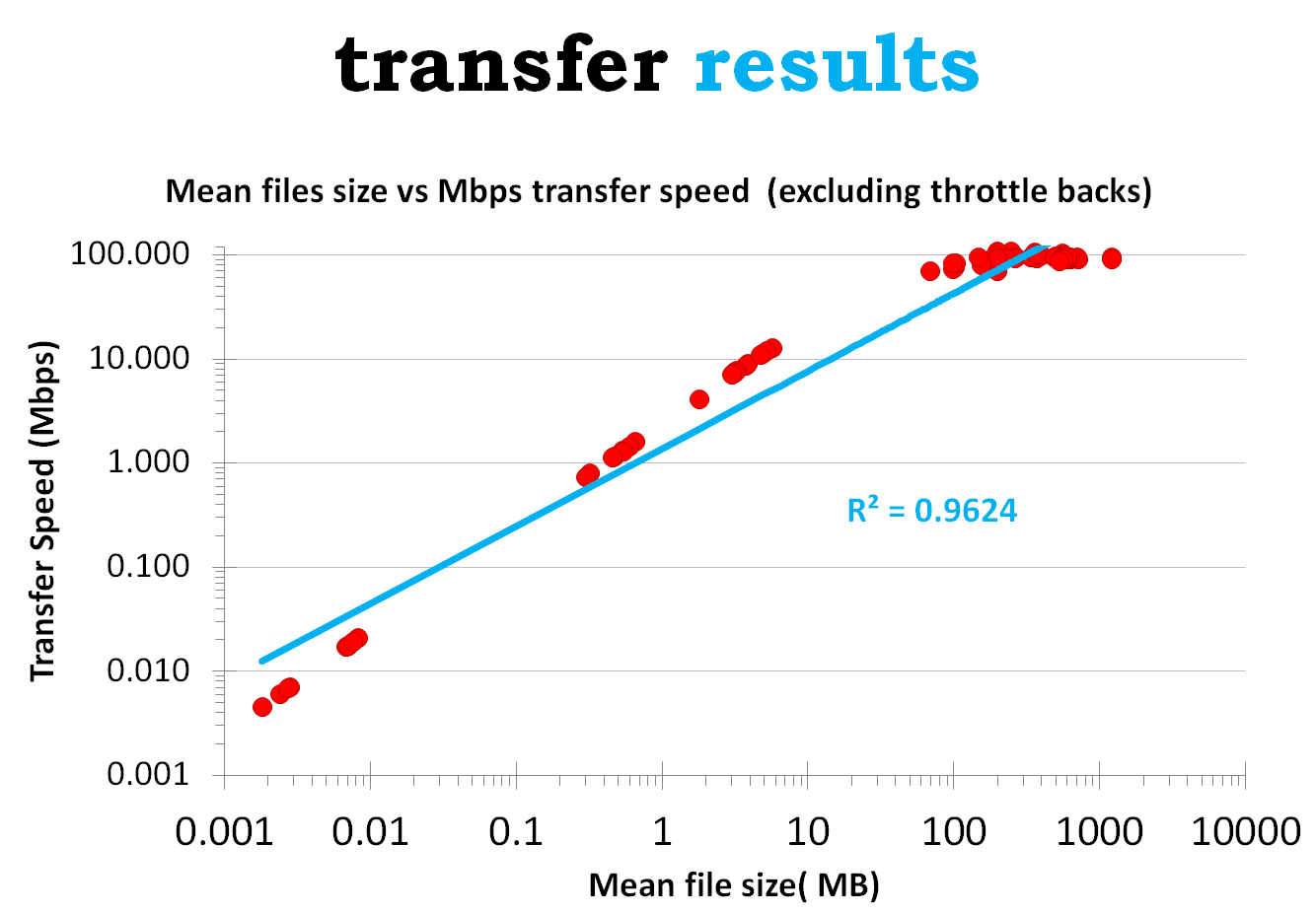
Figure 3: An analysis of the file size in a batch and transfer speed indicates that the smaller the files in the batch, the slower the transfer speed and vice versa.
An investigation into the unexpectedly slow speeds using online internet speed tests in conjunction with internal network monitoring tools revealed several useful things:
- different internet speed tests at different sites have significantly different download/upload speed performance which may be less than the bandwidth you want to test. These sites will underreport your internet speeds.
- Testing on www.speedtest.net (running the Adobe Flash interface and not the underperforming html5 beta.speedtest.net) seemed to fully exploit the Library’s 1Gbps connection.
- Running the test on the Ubuntu virtual machine gives around 300Mbps download and 400Mbps upload speeds.
- Running the test on the Windows host machine gives around 500-600Mbps download and 800-900Mbps upload speeds.
In summary uploading to iRODS/EPCC was 4-9 times slower than uploading data to the Internet and so a second investigation focussed on the overheads during the iRODS transfer and reporting process. The Cloudy Culture measurement of transfer speed includes all of the steps from reading the file from the computer to writing a line in the output report as described in the previous section on set-up. By reconfiguring the workflow and, for example, dropping the iRODS command to fixity check the file during transfer, speeds could improve by 4-22%. This is still much lower than the 4-9 speed increase expected.
A final investigation looked at using a Windows based web API to transfer files to EPCC. This would remove our iRODS configuration and the Ubuntu virtual machine as causes of a) the poor transfer speeds for batches of small files and b) the 109Mbps transfer ceiling. 2 batches were selected for upload using the same files that were previously transferred using iRODS. Transfer speeds using the web API were much faster than iRODs with both batches breaking our previous ceiling and setting new records of 122Mbps and 355Mbps - 10 and 3 times faster for batches of medium and large files respectively. While the transfer speeds are up batches with smaller files will still take longer to transfer than batches with larger files.
|
Batch label |
Total data size |
Number of files |
Mean file size |
Web API Mbps |
iRODS Mbps |
|
Medium file size |
200GB |
42348 |
4.8MB |
122 |
11.19 |
|
Large file size |
399.84GB |
833 |
491.5MB |
355 |
97.94 |
Figure 4: A comparison of transfer speeds for 2 batches of files using the iRODS service and the web API.
Conclusions
Ease of use.
Setting up iRODS in a Windows environment is, when compared to some of the well-known cloud storage services, complicated because you need to run a real or virtual Linux machine that bridges across to content, databases and file management that takes place in Windows.
There is sufficient documentation online to help you install a virtual machine, Ubuntu and the iCommands part of iRODS. Documentation of the iRODS database, iCAT, is patchy making it hard to construct custom queries for your data, but the iCommands documentation is clear and offers functionality that is well suited to digital preservation tasks, some of which will be covered in future Cloudy Culture reports. This functionality includes:
- uploading files from arbitrary locations to be placed in user defined locations
- undertaking fixity checks during transfer
- generating fresh checksums on the cloud copy as directed by the user to help identify if content changes over time
- identifying the location of files in iRODS using filenames, paths and other metadata (good for future fixity checks and downloads)
If you want to automate the transfer of files to the cloud using iRODS then you will need to create some of your own scripts to select the files and to put them into the cloud. This applies equally to other cloud storage services and the web API we tested unless you have a very simple arrangement of content at your local site. iRODS does not have a user interface but at its simplest uploading files into the cloud can be achieved using a series of iRODS “iput” commands pasted into a Linux bash script.
Reliability.
The iRODS service used in the project was reliable enough to be used as an in-principal 24 hours a day, 360 days a year service. The periods of interruption are at a manageable level where the manual intervention required for 4% of batches could be reduced with more coding. The workflow used was able to track, record and report on the transfer of the files by extending an existing database that the Library uses to manage its files. Fixity checks confirmed that no files were altered during the transfer and the recorded checksums and file paths will allow the Library to actively monitor the cloud copy over time.
Transfer speeds.
The National Library of Scotland has a bold ambition to make a third of its collections available digitally by 2020 which could mean producing 1-2PB of new digitised content per year. Based on our most optimistic view of the iRODS service the Library could upload a maximum of 0.4PB per year. In reality the mix of file sizes will reduce the transfer speed but with additional local processing files could be packaged in a wrapper format to maintain larger file sizes and the high transfer speed, although fixity checking is made more complicated. With an optimistic view of the web API uploader 1.3PB could be transferred per year, much closer to the Library’s 2PB upper target.
Final thoughts.
In conclusion an appropriate solution to reliably and quickly upload lots of digital cultural content into the cloud is provided through a unrealised combination of:
- the excellent network connection between the Library and EPCC
- iRODS preservation functionality
- Windows web API uploader speed and ease of installation
Although the services and connectivity described here are specific to the Cloudy Culture partners, all organisations thinking of uploading content to the cloud should consider, within their own contexts, the factors of ease of use, reliability and transfer speeds. What is your environment? What is your skills base to develop automation? Can you organise your content simply to allow user-friendly cloud storage tools to be used? Is your connection slower than the amount of data you want to upload? Is it better to post the data to your cloud storage provider them on big hard-drives like the Amazon Snowball? Have you factored in the other activities in your organisation that require an outbound and incoming network connection e.g. internet traffic including web API uploaders/downloaders? Are you able to allocate network bandwidth to different staff, PCs or activities to stop single users inhibiting other services?
In our final 2 reports, due for publication later in 2017, we will tackle some of the missing elements of this discussion such as downloading and recovery, routine fixity checking, running preservation tools in the cloud, and costs.