


















































































































































Dr Santhilata Kuppili Venkata is Digital Preservation Specialist / Researcher at The National Archives, UK
The Plain text file format identification is of interest for in the digital preservation area. At The National Archives (TNA), we have initiated the research to identify text file formats as the main topic. We carry on the research for the question: 'How to correctly identify the file type of a text file from its contents?'
Motivation to start this research and the dataset used for this purpose are discussed in part 1 published earlier. We present the methodology to the text file format identification as a classification problem in this part. As of now, we consider the classification of five formats - two programming source codes (Python and Java), two data file types (.csv and .tsv) and one text file type (.txt).
Methodology - ML to the rescue
Artificial Intelligence (AI) and Machine learning (ML) have become an integrated part of our lives. Machine learning is a set of generic algorithms that can understand and extract patterns from data and predict the outcome. TNA deals with a huge variety of file types for digital archiving. Hence an iterative process model is appropriate to include file types gradually. The methodology should be flexible enough to apply to more file types progressively. As and when a new file type is to be included, its features (specific characteristics) should be compared against the existing features and engineered to add to the list. Hyperparameters for the models should be adjusted accordingly to get a better performance. The flow graph in Figure 1 shows the methodology developed.
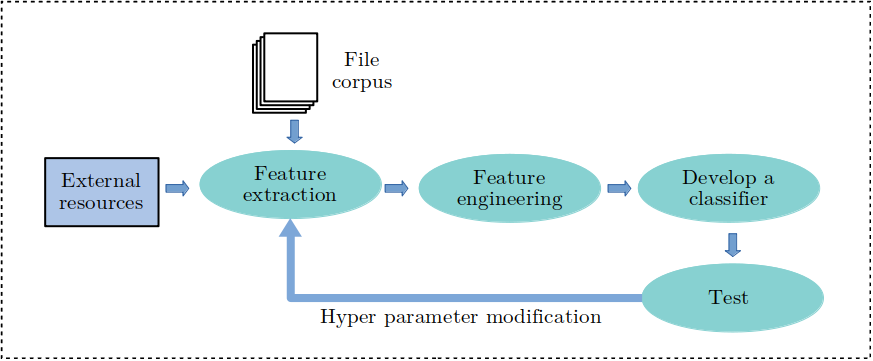
Figure 1: Methodology to add file formats progressively
Our file format identification problem proves to be the problem of classification based on the patterns extracted from non-linear data. By non-linear, we mean the number of correlated features shared by different file types. For example, .csv and .tsv files share a large number of file features. Similarly, there is a very high correlation between the Java and Python programming file structures. Many times a comma-separated file (.csv) contains unformatted lines of text. This leaves a very small difference while identifying formats between .txt and .csv files. Hence a non-linear model needs to be trained to identify a combination of features to identify a specific file type.
The file corpus consists of the files in the public repositories of Government Digital Service and TNA. A detailed description of File corpus is provided in part 1. With the modest amount of training data available (approximately 22,300 files), we divided the data into training-test sets in an 80:20 ratio. The External resources in the Figure 1 refers to the external tools (such as DROID), approaches and methods adopted in developing the models.
Feature Extraction:
A script is developed to identify the above features from the input data files. The code reviews each file line by line to extract the features. Feature extraction is done during the data pre-processing phase.
Feature generation & Engineering:
Feature generation is the process with which specific features and styles are extracted. Some of the above features are correlated to others so provide redundant information about the file. To reduce the processing overhead, we can feature engineer ( manipulate features) to keep highly relevant ones only. The feature engineering phase helps to identify salient characteristics of the data. Our data corpus consists of five types of files (.py, .java, .txt, .csv and .tsv) with structured and unstructured lines of text. So the first phase is to identify the features that describe these file types correctly.
Some of the considerations to generate features are as follows:
-
A Python source code file differs from Java source code by its commenting style, strict indentation at the beginning of each line, use of specific keywords etc. Similarly, the Java code needs to follow a predefined structure (for example, a semi-colon line delimiter) to be able to compile successfully.
-
By nature, programming codes have a specific internal structure. They differ from the text-based files by the structure.
-
Even though .csv and .tsv files are largely categorised as text-based, they can be recognised by the use of the number of commas (or other delimiter characters). But a .txt file got no restrictions on how to create one. It is difficult to extract a pattern from a normal .txt file. Hence we have used count of 'stopwords' (common words in English) from the NLTK library. We started with the assumption that that the usage of stopwords is more in normal text files than programming codes or data files.
-
Another significant characteristic used is the 'word-combination' proximity. For example, the combination of words such as <def-return>, <if-then-else> etc. are used more closely in the programming codes than .txt file.
A 3-layer neural network was designed to capture such patterns of a text file. In all, about 45 features were extracted and engineered for the identification of five file types.
Classifier Development:
There are supervised and unsupervised models to predict the class of a given data point. Selection of the model plays a significant role in the accurate prediction of a file type. We choose classification modelling (supervised methods) for the task. In the classification model, a classifier is applied to the features of the data to predict how much a file is similar to one class and different from another.
Testing:
Finally, the predicted outcome is tested to see the accuracy of the prediction model. The parameters are adjusted iteratively to improve the performance of the model.
Classification models & Evaluation
There are four prominent types of classification algorithms. they are, (i) Linear models, (ii) Tree-based algorithms, (iii) k-nearest algorithms and (iv) Neural network based algorithms. Since our problem has discrete outputs, we have omitted linear models.
Decision Tree classifier
A decision tree is a flowchart-like tree structure where an internal node represents a feature (or attribute), the branch represents a decision rule, and each leaf node represents the outcome. Each parent node learns to partition the data based on the attribute value. It partitions the tree recursively until all the data in the partition belongs to a single class. More details can be found here.
k-Nearest Neighbour classifier
The k-Nearest Neighbour(kNN) is a non-parametric lazy learning algorithm. In other words, there is no explicit training phase required for this model. The kNN algorithm is based on feature similarity which determines how we classify a given data point. More details can be found here.
Neural Network based classifier
A multilayer perceptron neural network is a non-linear classification model. A multilayer perceptron (MLP) is a deep, artificial neural network. It is composed of an input layer to receive the signal, an output layer that makes a decision or prediction about the input, and between those two, an arbitrary number of hidden layers. Training a neural network involves adjusting the parameters and the weights and biases of the model to minimize error. We have designed a 3 layer MLP to suit to the needs of the input dataset.
Evaluation
Out of the three classifiers mentioned above, the decision tree has obtained a highest accuracy with 98.58%. Where as k-NN's accuracy was 94.03% and MLP scored 97.37%. However, accuracy is not entirely a suitable metric when the distribution of classes in the input dataset is not uniform. So we consider precision scores to be the appropriate metric. The precision scores obtained (without hyperparameter tuning ) for the decision tree, k-NN and MLP are 82%, 74.03% and 89.32% respectively.
Conclusion
An initial prototype has been developed using the computational intelligence models for the project - Text File Format Identification. We have successfully established a flexible methodology so that more file formats can be included in future. We have achieved upto 98.58% accuracy in identifying the files. Even though, decision tree has performed well in accuracy, MLP had a better precision as expected.
In future, we could focus on revising the dominant feature identification for .csv and .tsv file types. Nearly 17% of .csv files were misidentified as .txt by the decision tree model. We need to address this issue in future. We have assumed that each .csv file contains only one table. However, it is possible that .csv files generated by the MS-Excel environment have multiple tables within a single file. This issue should also be investigated. Even though the current prototype works well for the five file types, a revision of feature generation and engineering will be necessary whenever new file types are introduced.