



















































































































































Ancient history: how we got here

Way back in 2013 the DPC collaborated with the OPF on a project called SPRUCE. Following on from the success of another little project called AQUA, and with some very handy funding from the Jisc, we ran a bunch of mashup events and got hands on with all sorts of digital preservation challenges. The management of PDF files, and particularly risk assessment, was a recurring theme. In response, the SPRUCE project held a hackathon in Leeds where a host of DP geeks came up with a basic proof of concept for a PDF risk checker. Based on PDFBOX – a PDF/A validator – and with denizens of both Yorkshire and Canada in the room (plus a variety of other nationalities) it seemed entirely appropriate to call it PDF/Eh? For those unfamiliar with Yorkshire dialect, this probably won't help but is recommended nonetheless. A number of important elements (that would surface again in the future) were brought together at this hackathon, but the participants recognised that this would take a much bigger push and a dedicated project to do it "properly".
PDF is a preservation problem almost everyone has. It's certainly not the biggest problem out there, but it needs some work and it's a little surprising that as a community we haven't managed to nail it. PDF/A is beginning to form part of the solution but a standard needs to be adequately supported with tools. That's where veraPDF comes in.
veraPDF: a validation tool for PDF/A
 Roll on to 2015 when a new consortium, again including DPC and OPF (but also Dual Lab, the PDF Association and Keep Solutions), began development of veraPDF. Funded by the EC through the PREFORMA project, the veraPDF consortium has leveraged the PDFBox tool through a series of development stages to create a new PDF/A validator. By bringing more precision to the table we hope to improve the general quality of PDF generation out there (and ultimately the PDFs in circulation), but also to provide a really useful tool for digital preservation. As the main development phase of the project neared completion in autumn 2016, we worked with DPC members and other interested parties to put the tool through its paces and provide feedback to fine tune the tool. We also had an opportunity to do some of our own testing. I set about applying veraPDF to risk assess some PDF/As, hoping in the process to identify any remaining bugs and to spot some opportunities to enhance the tool for digital preservation users. That's what I'm going to blog about here.
Roll on to 2015 when a new consortium, again including DPC and OPF (but also Dual Lab, the PDF Association and Keep Solutions), began development of veraPDF. Funded by the EC through the PREFORMA project, the veraPDF consortium has leveraged the PDFBox tool through a series of development stages to create a new PDF/A validator. By bringing more precision to the table we hope to improve the general quality of PDF generation out there (and ultimately the PDFs in circulation), but also to provide a really useful tool for digital preservation. As the main development phase of the project neared completion in autumn 2016, we worked with DPC members and other interested parties to put the tool through its paces and provide feedback to fine tune the tool. We also had an opportunity to do some of our own testing. I set about applying veraPDF to risk assess some PDF/As, hoping in the process to identify any remaining bugs and to spot some opportunities to enhance the tool for digital preservation users. That's what I'm going to blog about here.
Geek and proud
Having a few days to take on some more technical work was somewhat exciting (I guess I'm still a geek at heart?) but I was also a little apprehensive. Despite spending a lot of my youth writing code, I've since spent a long time in the murky world of middle management, Microsoft Word files, and other hellish things. Would there still be some geek skills hidden away in the old thinking box? Well, I didn't need to hack any code, but I did have a lot of fun working on the command line and getting back into some web and data stuff I'd previously tinkered with like XPATH. In contrast to the serious coding and unbelievable PDF mastery of my veraPDF colleagues at OPF and Dual Labs, it's all a bit trivial of course. But anyway, here's what I got up to....
Challenge 1: we built the most detailed test suite yet, but what about "real" data?
 veraPDF is underpinned by a fantastically detailed test suite that allows all the really specific validation rules to be checked. A whole cross section of testing from individual unit tests all the way up to some very thorough and automated build testing brings a lot to the functional quality of the tool and to the code quality (making subsequent maintenance and sustainability of the tool far easier). But how do we prepare for what the tool will face out in the wild? There are a growing number of test corpora ideal for testing digital preservation tools, but for our purposes we needed a decent number of real world PDF/As. As usual these were not easy to come by. A number of DPC members and other organisations were able to help us out, but issues with IPR and clearance can hinder sharing or just be impossible to negotiate. My experiences on big EC-funded projects in the past have been the same. ETH Zurich sourced us some rights-free PDF/A eprints which proved useful, but it was a fairly small set. With time moving on, I wondered what we could source from a web archive. I had a word with Andy Jackson at the BL, and of course, he was 3 steps ahead of me. Andy helped me deal with the quirkier syntax of his UKWA search interface – it's actually very good, but filtering by file format is not immediately obvious – and I quickly had a list of around a thousand PDF/A-1a files and PDF/A-1b files. Due to the terms of legal deposit legislation, the UKWA copies are disappointingly only available on site, but Andy has added a nifty facility that provides the URL of each file in the Internet Archive. A quick finesse of the URL list in Excel (strip out everything but the list of URLs of the files that I wanted) and it was over to the command line for my first ever "web crawling" with Wget. Very nice tool this. Just point Wget to the file that lists all your URLS and off it goes to fetch the files. I set it off running over night. By the morning, I had a pretty decent test set. Most of the files did seem to check out as PDF/As, according to Siegfried, but there were obviously a few oddities as well - just the sort of thing veraPDF might encounter in the wild. My hope and expectation was that this test set would consist of a really good cross section of files created by lots of different applications. This would be one of the first things to look into.
veraPDF is underpinned by a fantastically detailed test suite that allows all the really specific validation rules to be checked. A whole cross section of testing from individual unit tests all the way up to some very thorough and automated build testing brings a lot to the functional quality of the tool and to the code quality (making subsequent maintenance and sustainability of the tool far easier). But how do we prepare for what the tool will face out in the wild? There are a growing number of test corpora ideal for testing digital preservation tools, but for our purposes we needed a decent number of real world PDF/As. As usual these were not easy to come by. A number of DPC members and other organisations were able to help us out, but issues with IPR and clearance can hinder sharing or just be impossible to negotiate. My experiences on big EC-funded projects in the past have been the same. ETH Zurich sourced us some rights-free PDF/A eprints which proved useful, but it was a fairly small set. With time moving on, I wondered what we could source from a web archive. I had a word with Andy Jackson at the BL, and of course, he was 3 steps ahead of me. Andy helped me deal with the quirkier syntax of his UKWA search interface – it's actually very good, but filtering by file format is not immediately obvious – and I quickly had a list of around a thousand PDF/A-1a files and PDF/A-1b files. Due to the terms of legal deposit legislation, the UKWA copies are disappointingly only available on site, but Andy has added a nifty facility that provides the URL of each file in the Internet Archive. A quick finesse of the URL list in Excel (strip out everything but the list of URLs of the files that I wanted) and it was over to the command line for my first ever "web crawling" with Wget. Very nice tool this. Just point Wget to the file that lists all your URLS and off it goes to fetch the files. I set it off running over night. By the morning, I had a pretty decent test set. Most of the files did seem to check out as PDF/As, according to Siegfried, but there were obviously a few oddities as well - just the sort of thing veraPDF might encounter in the wild. My hope and expectation was that this test set would consist of a really good cross section of files created by lots of different applications. This would be one of the first things to look into.
Challenge 2: you're testing it because it's still in beta...
 The next step was to run veraPDF over the UKWA corpus and then start to examine the results. Unfortunately there were still a number of bugs in the way, so progress was a little slow. We'd had a few memory issues (yes it's written in Java) and some were still not ironed out, although most of our other testers (and DPC colleagues) were having no 'out of memory' issues by this point. What gives? My laptop isn't that old... The VM has copious gigabytes to play with... Still I found problems with specific files that were causing crashes. Still I had problems with validation runs that were crashing more erratically - sometimes when large files were encountered. I spent some time pulling out files that were causing crashes and repeating short runs with veraPDF to try and narrow down the problems. This led to some bug reports which I posted on Github. The UKWA corpus was proving quite useful. Although I couldn't share the files directly, I could very easily share them by reference by passing on their URLs to the devs. Recreating the bug is the first step to debugging, so this is invaluable. By this point I had a good chunk of XML generated by veraPDF (if not from the whole data set), so I could start to look at analysing it and pulling out information that I was interested in.
The next step was to run veraPDF over the UKWA corpus and then start to examine the results. Unfortunately there were still a number of bugs in the way, so progress was a little slow. We'd had a few memory issues (yes it's written in Java) and some were still not ironed out, although most of our other testers (and DPC colleagues) were having no 'out of memory' issues by this point. What gives? My laptop isn't that old... The VM has copious gigabytes to play with... Still I found problems with specific files that were causing crashes. Still I had problems with validation runs that were crashing more erratically - sometimes when large files were encountered. I spent some time pulling out files that were causing crashes and repeating short runs with veraPDF to try and narrow down the problems. This led to some bug reports which I posted on Github. The UKWA corpus was proving quite useful. Although I couldn't share the files directly, I could very easily share them by reference by passing on their URLs to the devs. Recreating the bug is the first step to debugging, so this is invaluable. By this point I had a good chunk of XML generated by veraPDF (if not from the whole data set), so I could start to look at analysing it and pulling out information that I was interested in.
Challenge 3: go where no XML parser has gone before (and hope you're not the one wearing a red shirt)
 I hadn't yet discovered the veraPDF configuration file that allows you to control which feature extraction modules are executed. The default setting is now much more sensible (meaning less verbose) and further configuration options are coming soon (as well as more documentation for the otherwise straightforward CLI tool). As it was, I still had megabytes of XML for just a few files - automation would be essential. I started poking around, first in a couple of XML viewers to ascertain what goodies were on offer in the XML. Then I did a bit of cautionary XPATHing so I could pull out the contents of tags I was particularly interested in, for each file in the test set.
I hadn't yet discovered the veraPDF configuration file that allows you to control which feature extraction modules are executed. The default setting is now much more sensible (meaning less verbose) and further configuration options are coming soon (as well as more documentation for the otherwise straightforward CLI tool). As it was, I still had megabytes of XML for just a few files - automation would be essential. I started poking around, first in a couple of XML viewers to ascertain what goodies were on offer in the XML. Then I did a bit of cautionary XPATHing so I could pull out the contents of tags I was particularly interested in, for each file in the test set.
I'd used the XMLstarlet tool a few times before. It does a number of different things, so the documentation is a little intimidating, but for simply interrogating some XML and pulling out particular pieces of information that you're after it can be quite elegant and certainly very powerful. For those unfamiliar with it, this is a gentle but informative introduction and there'll be more on this in part 2 of this blog.
 After some initial rooting around with XMLstarlet, nothing was working exactly as expected. I spent a bit of time double and triple checking my work, out of practice at this sort of thing as I was. I made a few fixes, but something else was going on. I realised I'd dropped into proper debugging mode. Wow, it has been a long time! I'd almost forgotten how infuriating but also completely absorbing and addictive this sort of thing can be. I moved closer and was getting some reasonable output of some of the metadata fields, but some of the XPATH queries were returning nothing. Convinced something else was going on (and with hindsight where I should of course had started) - some XML validation was in order. A quick well-formedness check revealed some bad UTF8 characters. My XPATHing was fine, but veraPDF was generating some slightly smelly XML. These bad characters were showing up in the veraPDF output from a couple of sources, mostly the metadata fields of my UKWA PDFs. This hadn't been enough to completely break either my XML viewers or XMLStarlet, but it did corrupt their operation and it did stop me making progress.
After some initial rooting around with XMLstarlet, nothing was working exactly as expected. I spent a bit of time double and triple checking my work, out of practice at this sort of thing as I was. I made a few fixes, but something else was going on. I realised I'd dropped into proper debugging mode. Wow, it has been a long time! I'd almost forgotten how infuriating but also completely absorbing and addictive this sort of thing can be. I moved closer and was getting some reasonable output of some of the metadata fields, but some of the XPATH queries were returning nothing. Convinced something else was going on (and with hindsight where I should of course had started) - some XML validation was in order. A quick well-formedness check revealed some bad UTF8 characters. My XPATHing was fine, but veraPDF was generating some slightly smelly XML. These bad characters were showing up in the veraPDF output from a couple of sources, mostly the metadata fields of my UKWA PDFs. This hadn't been enough to completely break either my XML viewers or XMLStarlet, but it did corrupt their operation and it did stop me making progress.

Again I posted a Github issue. A further complication was that some of the XML output was a little messy with namespaces left, right, and centre and some quirky structuring of a few of the tags I was after. With all these issues combined, it required an XPATH query from hell, and it *still* didn't work correctly.
In the thick of this work I surfaced from a marathon session at 1 in the morning. Aside from working on face to face events, the longest day’s work I've done since, well, since I was programming for (some kind of) a living. At this point it was clear that I was still a bit of a geek, but more importantly I had not entirely lost my geek skills(TM).
Challenge 4: (you hope) the dev team is your friend
 At this point my veraPDF work was interrupted by first the Digital Preservation Awards and then a holiday, but this was perfect timing. Within a day of my return a new version of veraPDF was on the streets with fixes for all the bugs I'd reported. Even better, the remaining memory niggles also appeared to be completely vanquished. Digital preservation tools don't have a fantastic reputation when it comes to bug fixing but I was lucky enough to rely on a fantastic team at Dual Labs who were working full time on development and had quickly picked up issues I'd reported. Further work from Carl Wilson at OPF had also come into play and the latest release now runs like a dream. It's certainly worth emphasising that although the hard work of fixing bugs comes from the devs, reporting issues on Github is *incredibly* useful and is super easy to do.
At this point my veraPDF work was interrupted by first the Digital Preservation Awards and then a holiday, but this was perfect timing. Within a day of my return a new version of veraPDF was on the streets with fixes for all the bugs I'd reported. Even better, the remaining memory niggles also appeared to be completely vanquished. Digital preservation tools don't have a fantastic reputation when it comes to bug fixing but I was lucky enough to rely on a fantastic team at Dual Labs who were working full time on development and had quickly picked up issues I'd reported. Further work from Carl Wilson at OPF had also come into play and the latest release now runs like a dream. It's certainly worth emphasising that although the hard work of fixing bugs comes from the devs, reporting issues on Github is *incredibly* useful and is super easy to do.
Challenge 5: putting it all together (aka the easy bit)
With the bugs squashed, the XML tidied, and the memory troubles a thing of the past, it immediately became clear how easy veraPDF is to use, and how powerful it can be. I could now do a run over my UKWA test and a quick bit of XPATHing (now incredibly simple) with XMLstarlet, and whack, I've got a nice spreadsheet with some interesting metadata fields to play with. Obviously there are a multitude of ways to work with a CLI tool and it's XML output, but the cycle of tool run->extract from XML to CSV->analyse->rinse and repeat is a good place to start (although a profile checker for veraPDF is on the way). The results were just what I was after, and although it was a bumpy journey to get to this point, the UKWA sourced test corpora was perfect for tracking down a few of the remaining issues with veraPDF. Version 1.0 of veraPDF is now available for download, and I'd encourage you to try it out.
Challenge 6: the answer is 42, but what was the question (again)?
This is a sample of the per file output, picking up summary details of the validation run (how many validation rules each particular file had broken) and a few extracted metadata fields of interest such as the creating application.
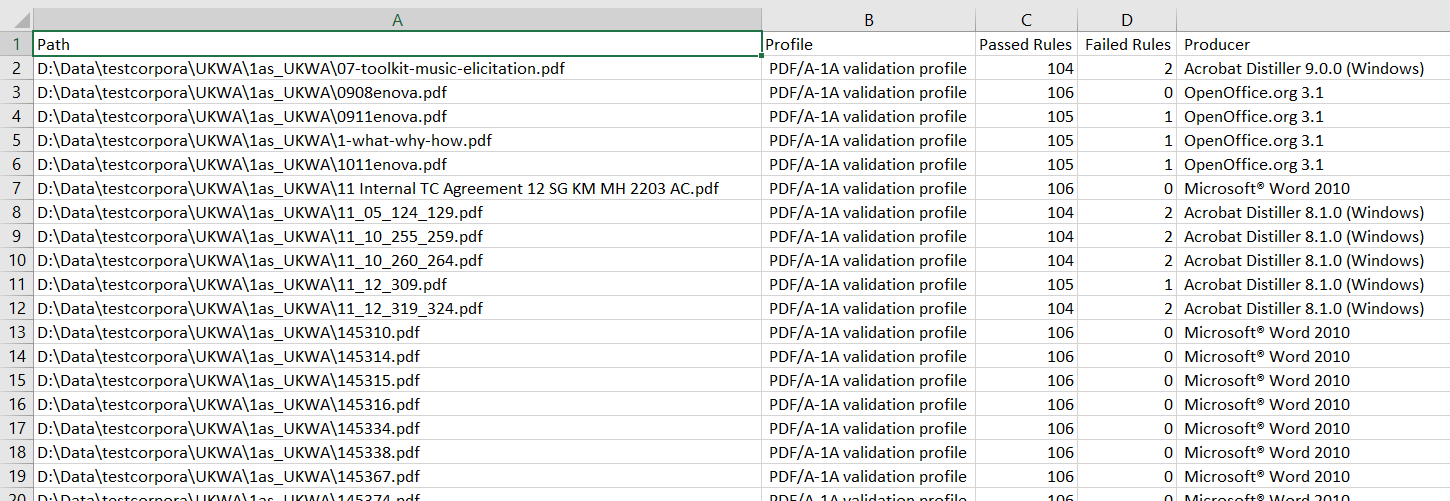
The temptation then was to play around with the data in Excel and order things by creating application. Nice and easy to do this in Excel. Which apps were making lovely shiny compliant PDF/As and which were the bad guys, churning out nothing but PDF/A headers and distinctly vanilla PDF bodies? This is what I came up with:
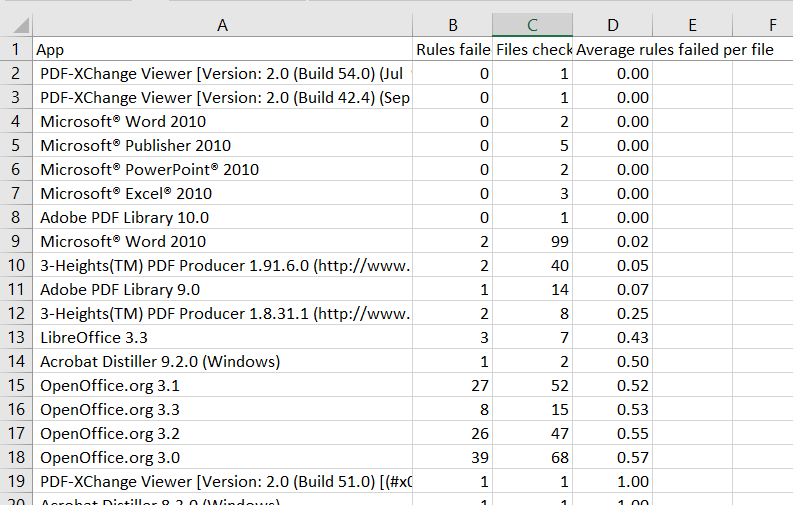
At which point you realise this is a completely false result. There are a multitude of reasons for this, but here are the three big ones. First, the sample size is waaay too small and some applications are represented by only a small number of files. Second, a count of the number of rules broken is frankly beyond crude. And third, the significance of the rules broken is not taken into account. Addressing the first two requires a bit more finesse in the analysis and a bigger raid of the IA. The third requires a much deeper interpretation of the validation results. This would also enable us to apply veraPDF as a kind of risk assessor of both PDF/As and perhaps also vanilla PDFs. Something we hope to move towards soon. So for the moment this is just a pointer to the future potential of this work and the possibility to identify and report bugs in PDF/A creation tools.
That's part 1 of my command line journey with veraPDF. In the second part I’ll guide you through the process of validating your PDFs and working with the results.
GIFs were mostly cheekily looped from the WePreserve Project's fantastic Digiman series.