


























































































































ePADD is free and open-source software developed by Stanford University Libraries and partners that supports the appraisal, processing, preservation, discovery, and delivery of email archives ofpotential historical or cultural value. Over the past five years, ePADD has pioneered the application of machine learning and natural language processing to confront challenges that collection donors, archivists, and researchers routinely face in donating, administering, preserving, or accessing email collections. This includes screening email for confidential, restricted, or legally-protected information, preparing email for preservation, and making the resulting files (which incorporates preservation actions taken by the repository) discoverable and accessible to researchers.
Email offers singular insight into and evidence of a person's self-expression, as well as records of collaboration, networks, and transactions. Email communications of prominent individuals, including politicians, writers, scholars, and the like, reveal not only their professional and personal actions, decisions, and creative output, but also relationships within society and communities. Thus, the appeal of email collections extends beyond historians to all manner of researchers, journalists, and the general public seeking to obtain insight into individuals and their transactions. Because use of email is so ubiquitous and email records provide insight into civic, artistic, and scholarly undertakings, archival institutions of all types increasingly seek to acquire email collections.
ePADD incorporates several automated functionalities which help simplify screening and optimization of access to the email archive's intellectual content. This work, which takes place during the initial import of email into ePADD, supports all subsequent activities by donors, cultural memory institutions, and researchers. First, ePADD resolves names and email addresses associated with a single correspondent. Resolved correspondent names can be browsed and graphed alphabetically or by volume of messages exchanged with the email account holder. Second, ePADD employs a custom fine-grained named entity recognizer that extracts categories of entities bootstrapped from DBpedia. These include persons, organizations, locations, government entities, political parties, companies, universities, diseases, and awards. Extracted entities can be browsed alphabetically or by volume of messages. Named entity recognition effectively convert unstructured data (the email message body) into structured data which can be queried and browsed.
ePADD also provides donors and the staff of memory institutions with an integrated toolset to efficiently carry out appraisal and processing of email in archival collections. The toolset has been designed to meet the specific challenges of appraising and processing email outlined above. These tools include keyword search, advanced search, regular expression search, a customizable “lexiconsearch,” which enables tiered thematic searching across several categories, a “multi-entity search” to aid in comparative entity analysis between the archive and any other textual corpus, image attachment browsing, mailing list identification, graphical visualization, user annotation, and an interface for assigning authorized headings to correspondents. Messages may be annotated and tagged with labels indicating terms of restriction (which will not export to subsequent modules).
All of ePADD’s functionality is made available through an intuitive and user-friendly graphical user interface, ensuring that relatively non-technical individuals will be able to carry out the functions required to make email archives accessible for research. In fact, ePADD is designed to optionally enable email creators, in partnership with curators and digital archivists, to use the software to review their email at scale to help identify and mitigate issues of confidentiality and copyright priorto transfer. These challenges often present a hindrance or outright blocker to transfer. In this way, ePADD helps ensure the availability of these materials to subsequent digital preservation processes and access.
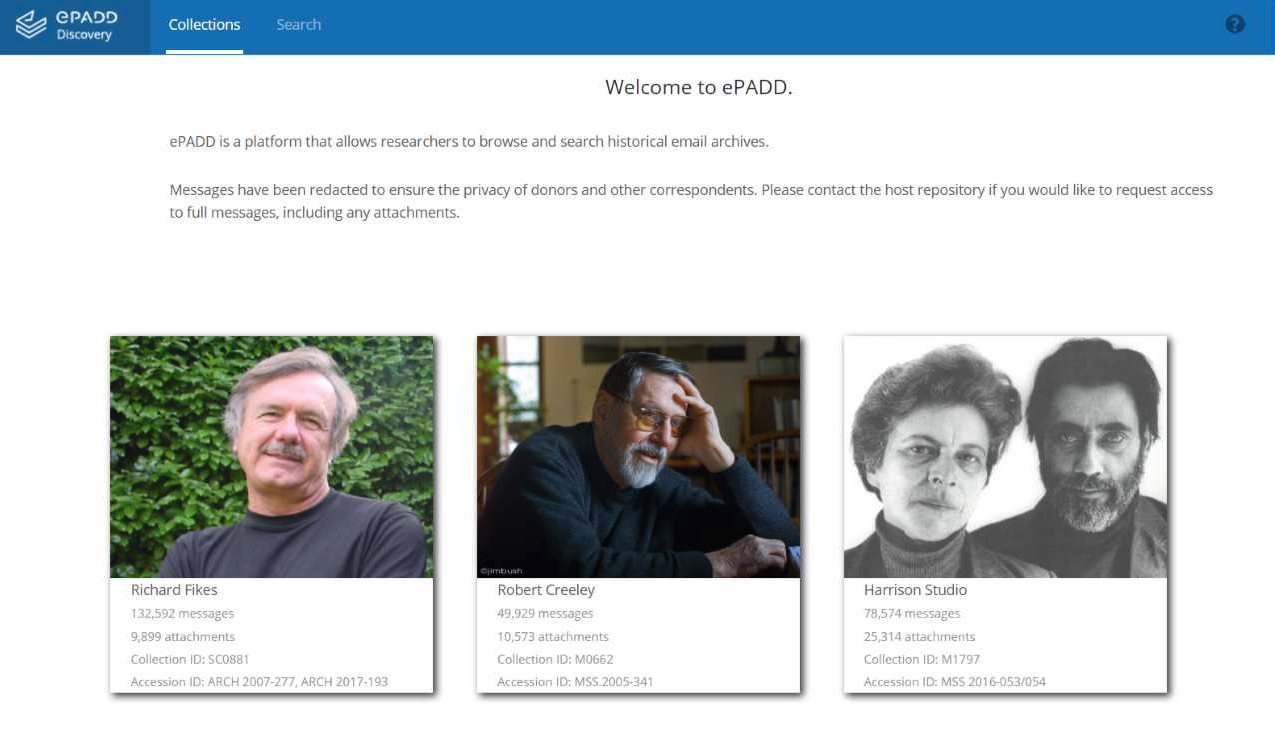
ePADD’s automated functionalities, including the resolution of correspondent names and recognition of fine-grained entities, also directly benefit scholarly researchers. Before institutions adopted ePADD, researchers faced challenges discovering and accessing email in archival collections. Even after the materials were collected and processed, email was not made available online to the public because of the same privacy and copyright concerns. As description made available online in archival finding aids and catalog records was often very limited, it was difficult for researchers to make the case that it was worth the resources to travel to the host institution to view the materials. In order to help address these issues, ePADD introduced a Discovery module, which enables researchers to access a redacted version of the email archive via a public web server prior to visiting the repository. This conceit inverts the traditional model of redaction by displaying only the correspondents and named entities, and relies heavily upon ePADD's automated resolution ofcorrespondent names and extraction and classification of fine-grained entities. The Discovery module enables even those remote users who are unfamiliar with a collection to browse across itvia these same correspondents and entities.
Once a researcher has discovered the email archive and decided to view it, a repository can use ePADD to enable access to the full archive of unrestricted messages, including attachments, via an interface that offers many of the same functionalities included in other modules. ePADD also supports a variety of exports of controlled data from the archive, to support accessing collections as data: network analysis, topic modeling, and other research by scholars. It is not enough to provide access to the mail; it is also important to ensure the email is processed in a way that supports digital preservation best practices, and that it can be easily shared with a digital preservation repository. In addition to adopting the Bagit specification to enable checksum verification and ensure file integrity, we have also modeled an integration with Archivematica. Not only can ePADD prepare the Archival Information Package (AIP) for Archivematica, it can also make the Dissemination Information Package (DIP) discoverable and accessible to researchers; the software can identify preservation actions performed on ePADD bags by Archivematica, including filename clean-up and file migration, and provide access to both original files and migrated files.
By pioneering the application of machine learning and natural language processing to address challenges facing the cultural heritage community, ePADD has enabled a broad and diverse constituency of libraries, archives, and museums to collect, preserve, and provide access to vital cultural heritage materials that would otherwise be unavailable for research.
