



























































































































Bish Back Backup is a student blog that focuses on preservation metadata and it reports on a project to create a simple but innovative tool for implementing PREMIS in XML by automatically extracting and converting metadata into PREMIS-complaint format.
The project was carried out over the course of the Digital Curation module (10 weeks) in class and during independent study time and is linked to both the class intended learning outcomes and the personal learning outcomes identified by students in week 1. This student blog received a distinction and the highest grade in the cohort, demonstrating a precise grasp of preservation metadata as a sustainability and professional issue and executed to an extremely high standard across all the criteria assessed (communication, contextualization, analysis and synthesis, presentation), as well as to a professional standard beyond the course requirements. A key challenge of this assessed work is to balance technical and practical aspects with appropriate detail and tone of communication, as well as being clearly situated in a wider body of professional discourse and practice, while also maintaining academic rigour. This blog achieves this with great clarity and attention to detail in both content and visual communication.
The Bish Bash Backup blog first reflects on the significance of preservation metadata, then it considers different schemas (PREMIS, METS, TOTEM) in order to set the scene for PREMIS implementation. One of the class activities during the module was to manually build a simple PREMIS XML (eXtensible Markup Language) schema using Excel and Oxygen (a free XML editor) and to map metadata from other sources such as the file identification tool DROID and using the PREMIS Data Dictionary in order to gain a deeper understanding of metadata mapping and basic skills in using an XML editor to transform data. This project also used XML as the basis to explore PREMIS implementation, reflecting particularly on the utility of automation given the complexity of working with such metadata schema manually and the “data deluge”. The blog also reflects on the high bar (and sometimes cost) of getting to grips with larger digital repository systems that support PREMIS, as well as the limitations of other “small” tools aimed at generating PREMIS-compliant metadata. The blog therefore identifies a gap in standalone “medium” tools available for converting detailed PREMIS XML from a target file.
Figure 1: Logo for Bish Bash Backup Blog. Image: Alex Habgood.
The resulting prototype, “Premissh”, was developed for the Linux Command Line: “a BASH script that can automatically generate PREMIS XML for an input file(s).” The tool uses third-party applications DROID and ExifTool to extract the necessary metadata from the input file and this is converted to PREMIS XML using and XSLT (eXtensible Stylesheet Language Transformations) script. The code functions successfully and the blog reflects on the limitations of the prototype and areas for continued development e.g., the ability to change which metadata elements are included in the output metadata file.
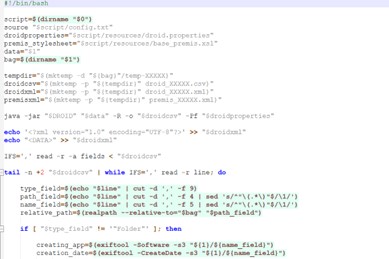
Figure 2: Excerpt of code, from an early version of Premissh. Image: Alex Habgood.
Crucially, the blog reflects on whether digital curators need to learn to code and where a project like this sits within that context. While the student concludes that not all digital curators needs to code, they reflect on how the development of their own coding skills “opened up new avenues… to solve problems with digital technology” and grow their “knowledge of the underlying functionality of digital technologies”, which ultimately could serve as generative way for digital curation professionals to improve their digital literacy.
Figure 3: GitHub page for Premissh where the code is publicly accessible for others to use. Image: Alex Habgood.
The development of a novel tool, going beyond learning and critically examining an existing tool, exceeds the requirements of the blog assessment and directly contributes to professional practice. The code was also developed to be FOSS (free and open source) and the source code has been made publicly available without restrictions via GitHub, underlining the extensibility of the work. Additionally, it was shared on social media with the aim of eliciting feedback from fellow professionals and identifying areas for future improvement, being both well-received and generating insights for the blog itself and for the future development of the tool. Again, this testing and deployment went beyond the elementary requirements of the assessment to bring in professional collaboration.
Planning ahead for DVD-Video migration research
Starting with complexity: Archiving digital-born music compositions from Mac systems of the 80s/90s