









































































































































Part 4: Costs and tools
The National Library of Scotland, Edinburgh Parallel Computing Centre, National Galleries of Scotland and the Digital Preservation Coalition are working together on a project called Cloudy Culture to explore the potential of cloud services to help preserve digital culture. This is one of a number of pilots under the larger EUDAT project, funded through Horizon2020.
We’ve already published an introduction to Cloudy Culture and reports on uploading and file fixity and downloading. This final report covers the use of preservation tools in the cloud using MediaInfo as an example, and the costs of using the cloud. The costs are based on a cloud service hosted by the Edinburgh Parallel Computing Centre (EPCC) using iRODS data management software (https://irods.org). The research questions we ask are:
- Can we use arbitrary preservation tools e.g. MediaInfo, in the cloud, even when the cloud uses one operating system and the tools run on another?
- How quickly did the tool run?
- How do EPCC cloud service costs compare to local storage and Amazon Cloud costs?
Can we use arbitrary preservation tools?
The National Library of Scotland uses a range of 3rd party software tools to help normalise, ingest, manage and preserve digital content. For example tools are used for zipping, jp2 conversion, image analysis and metadata extraction. MediaInfo is one such tool that provides the Library with an easy way to extract technical metadata such as codecs from audio-visual files, and it can provide standard information like byte size and pixel dimensions. Crucially it has command-line functionality that makes it easy to integrate it into automated workflows.
During the upload phase of the project we had placed files in a succession of batch folders and so our aim was to issue a single command for each batch that would result in a single MediaInfo report file that we could download and parse. We didn’t want to issue a million commands for the million files we’d uploaded, although it is equally possible to target individual files in this way.
EPCC provides cloud services for the project using iRODS data management software. One of iRODS’ many benefits is the ability to create custom-built microservices, jobs that the remote cloud user can run at specific times using the iexecmd command. To report on a batch folder containing up to 67768 files and to get around an iexecmd hard-wired buffer limit that limits the amount of information that can be sent back to the user we created 2 scripts that worked in unison run from a single command like this:
# run remote command to get list of filenames
iexecmd -v -H $HOSTNAME "rlist $pathToCollectionYouWantToProcess" > $pathToTemporaryFileWhichListsTheFilesInTheCollection
iexecmd -v -H $HOSTNAME "minfo $pathToTemporaryFileWhichListsTheFilesInTheCollection" >> $reportFileContainingMediaInfoResults
The first “rlist” script takes a supplied folder/collection path and then lists the files within it. The second “minfo” script works through the list of files and runs MediaInfo against them reporting the results to a report made available to the cloud user. A section of the report looks like this:
Processing directory /some-server/iRODS/somefolder/home/someuser/batch101
Thu Jun 1 07:57:43 BST 2017
General
Complete name: /some-server/iRODS/somefolder/home/someuser/batch101/75105043.1.tif
Format: TIFF
File size: 576 MiB
Image
Format: Raw
Width: 17 054 pixels
Height: 11 800 pixels
Color space: RGB
Bit depth: 8 bits
Compression mode: Lossless
Thu Jun 1 07:57:43 BST 2017
Extracting information for everything we uploaded was as easy as looping through the names of all the batch folders in an extension of the script above. One click and leave. Simple.
As well as extending this “process and report” approach to other preservation tools you could extend it to include tools that run in different operating systems. In addition to using the Unix version of MediaInfo we also successfully tested the Windows version by running it through WINE (https://www.winehq.org/about) which allows Windows applications to run on Unix. In theory this approach could be used for any application that can run from a command-line and is compatible with the emulator although performance would be expected to be worse than running the tools natively.
How quickly did the tool run?
The cloud service, running Media Info, took 72 hours to process 429,910 files amounting to 2821GB. This converts to a processing speed of 5971 files an hour or 39GB per hour. To calculate future processing time use file count as the predictor and not file size as MediaInfo analyses discrete chunks of information from files and does not need to open them fully.
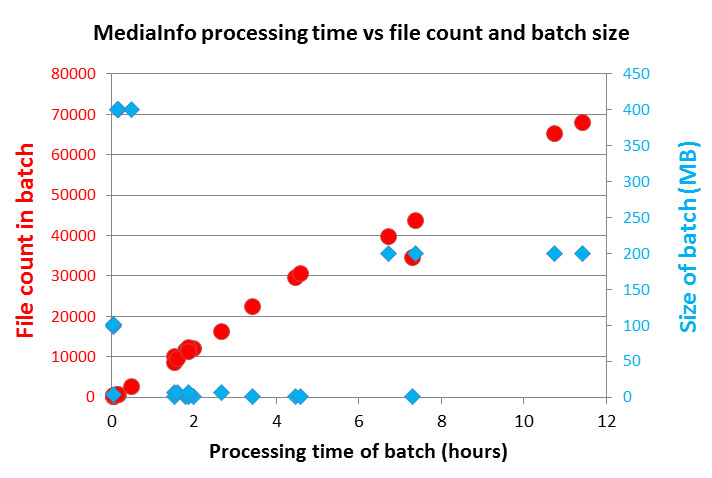
Figure 1: Plot showing MediaInfo processing time vs file count and batch size
How do EPCC cloud service costs compare to local storage and Amazon Cloud costs?
The Cloudy Culture project partners have been in the fortunate position to be able to test EPCC cloud services for free thanks to the generosity of EPCC and funding from the EUDAT parent project. To make our research more widely relevant we applied real-world costs to the amount of data we uploaded, stored, processed and downloaded to allow others to map these costs to their own circumstances. Does the cloud offer the functionality you need at the price you can afford, or will other forms of storage be better?
In Table 1 we explore three scenarios for preservation services that correspond to the needs and activity of the Cloudy Culture project:
- EPCC cloud service
- National Library of Scotland local storage
- Amazon web services (S3 storage + EC2 computing)
Broadly speaking we uploaded and stored 30TB (1 million files) for 16 months, fixity checked all of the files once (and some twice), extracted metadata using MediaInfo from half of the files, and downloaded 3.5TB (0.4 million files) of data. Each scenario is designed to support this activity.
Please bear in mind that: other scenario configurations are available and will dramatically affect the cost; the three scenarios explored do not offer exactly the same benefits; costs are illustrative for the EPCC and the National Library of Scotland services, and theoretical for Amazon as we did not test this service. Furthermore we excluded the development costs to automate data management and the cost of the customer’s time to interact with the services. Finally we assume that the data is loaded all at once to the service and does not change so that the monthly storage costs are flat.
|
Cost component |
EPCC cloud service cost (1 disk + 2 tape copies) |
National Library of Scotland local storage (1 disk + 1 tape copy) |
Amazon S3 infrequent access storage and EC2 (data distributed over 3+ facilities) |
|
Storage - 29588GB for 16 months |
0.0474 per GB + 453.95 per month = 29,702.74 |
0.0321 per GB per month = 15,196.40 |
0.0131 per GB per month +20GB penalty = 6,205.84 |
|
Put/upload requests - 1177345 files |
Included in storage costs |
N/A |
0.0053 per 1000 = 6.24 |
|
Get requests - Fixity (1,234,528 files, 29989GB) + MediaInfo (529,484 files, 2821GB) + Download (429910 files, 3522GB) |
Included in storage costs |
N/A |
0.0042 per 10,000 = 0.92 |
|
Download - 3522GB in 32 days |
Included in storage costs |
N/A |
0.090 per GB minus 2 free GB = 316.80 |
|
Fixity and MediaInfo processing time - 428 hours |
Included in storage costs |
Included in storage costs |
420 GB of EBS storage @ 0.116 per GB per month = 28.74 + c4.large instance for processing @ 0.119 per hour = 50.93 = 79.67 |
|
Total cost USD |
29,702.74 |
15,196.40 |
6,609.47 |
|
Total cost GBP |
22,574.08 |
11,549.26 |
5,023.20 |
* Pricing and conversion based on October 2017 values in USD unless stated otherwise. Amazon costs are for the EU (London) region (see https://aws.amazon.com ) and conversion is 1 USD = 0.76 GBP
Table 1: Estimated costs using Amazon S3 + EC2, EPCC and National Library of Scotland to undertake Cloudy Culture preservation activity.
A PERILOUS LOOK AT THE INSIDES OF THE 3 PRESERVATION SERVICES
EPCC provided the cloud services for the entire Cloudy Culture project which used the UK Research Data Facility http://www.archer.ac.uk/documentation/rdf-guide. For Cloudy Culture a main container ran on one of the DAC nodes for the iRODS service as part of “lite” version of a larger software suite called B2SAFE provided by the EUDAT parent project. A secondary container was also provided for the small amount of testing we did using HTTP uploads. Data was stored as 1 disk copy and two back-up tape copies. The costs include storage, network transfers, processing, storage system running costs, staff and the provision of the service. EPCC staff costs are rolled into the storage costs.
National Library of Scotland storage costs include today’s rates for storage media, processor, networking, energy consumption, maintenance contracts, licenses, cyclical system replacement, and staff costs. Staff costs include maintenance, development, procurement, implementation and planning activity associated with networks, machines, and storage. Data is stored as one disk and one tape copy.
Amazon Web Services costs are modelled on S3 standard infrequent access storage with data transferred to Amazon EC2 to run fixity checks and MediaInfo. A sufficient match to replicate the EPCC set-up is one c4.large instance plus 3 EBS general purpose SSD volumes at a total of 420GB to store the operating system, database and batches of files that are being processed. The “infrequent access” option has more accepted downtime, but the same access times as S3 “standard” when it’s running. It introduces a 20GB penalty because of the amount of small files Cloudy Culture would store but reduces the storage cost component by almost a half.
Conclusions
Tools
Running tools in the cloud and adopting the “process and report” approach meant that we did not need to download hundreds of thousands of files from the cloud to process them. This saves download time and while it introduces additional transfer and compute costs these are shown to be a trivial component of the overall costs in the Amazon scenario. What’s more cloud services can be configured to run any tool that runs on popular operating systems.
Costs and benefits
Using Amazon would have cost less than a quarter of the price of the EPCC preservation service and less than half of the price of the National Library of Scotland’s local service. Remember that each service offers different benefits so this is far from a like-for-like comparison. Even so the economic case for using low-cost commercial cloud is compelling. In order for the National Library of Scotland’s local storage to be competitive we would need to wait 4 years while all storage costs reduced by 20% year on year - and assume that Amazon pricing remains flat.
The cloud service offered by EPCC was fantastic and with the exception of upload/ingest speeds all of our requirements were met. Processing speeds were faster than the local processing undertaken at the National Library of Scotland and EPCC offered transparent and testable processes so the customer can fully understand, for example, how it performs fixity checking. What’s more an additional back-up was offered.
The role of the cloud in preserving digital cultural heritage
If we imagine that low-cost commercial cloud providers such as Amazon can provide the services of EPCC then cost becomes an incentive and not a barrier to using cloud for the preservation of digital cultural heritage. The project suggested alternative workflows for overcoming transfer speed issues and successfully demonstrated data processing in the cloud. So if the cloud is this good why would you keep a local copy at all?
One position would say that governance and distributing risk are the sole remaining reasons to keep a local copy of preservation data. Many institutions have a mandate, sometimes a legal one, to safeguard their business assets, sensitive data or digital cultural heritage. Devolving some control and all copies of their data to third parties may not be appropriate. And is it OK for organisations funded by the public to abandon direct responsibility of data for the public?
Cloud services run on networks that are exposed to the network risks that can affect us all. Compromised accounts and loss of services have affected Amazon within the last year and they are not alone. National institutions, businesses and governments have also been affected. And what if the business stops offering cloud services? Have you got a disaster recovery plan if you can no longer access your cloud data? One approach is to spread copies across different technologies, environments and locations to counter as many of the risks to data loss as you can. Having one local copy and another in the cloud is a way to do that.
Today the National Library of Scotland stores 1 copy of data on offline tape and 1 on disk, and has plans to store another copy on disk. With a clear understanding that preservation activity can successfully take place in the cloud and on the proviso that the costs remain beneficial a logical step over the next 5 years would be to shift towards 1 copy on local disk, 1 copy in the cloud and 1 kept on offline media. This lowers costs, puts 3 copies on 3 different technologies, in 3 different operating environments, in 3 different physical locations and with one copy kept offline - all to protect against a wide range of threats.
To reach this conclusion would not have been possible without the project partners and so many thanks are due to the National Galleries of Scotland, the National Library of Scotland, the Digital Preservation Coalition, our EUDAT project parent and last but not least, the Edinburgh Parallel Computing Centre.