









































































































































Part 3: File fixity and downloading
The National Library of Scotland, Edinburgh Parallel Computing Centre, National Galleries of Scotland and the Digital Preservation Coalition are working together on a project called Cloudy Culture to explore the potential of cloud services to help preserve digital culture. This is one of a number of pilots under the larger EUDAT project, funded through Horizon2020.
We’ve already published a friendly introduction to Cloudy Culture and a report on uploading files to the cloud and readers are encouraged to look there for details about the systems, tools and technical infrastructure used by the project. This third of four reports focuses on file fixity and downloading data from the cloud service hosted by the Edinburgh Parallel Computing Centre (EPCC) using iRODS data management software (https://irods.org).
The report will answer the following questions before making some concluding remarks:
-
Can we use fixity checks in the cloud to ensure that the files we send to the cloud don’t change while they are there?
-
Can fixity checks happen faster in the cloud than the local checks?
-
Have any of the files in the cloud service changed undesirably?
-
How do you download and is it reliable?
-
How quickly can we download digital content from the cloud service?
Can we use fixity checks in the cloud to ensure that the files we send to the cloud don’t change while they are there?
Fixity checking is a great technique to check if files remain the same over a period of time. You can let a computer scan millions of files to create a fingerprint for each, called a checksum, which you can store as a string of text for later comparison. If the checksum has changed between checks then the file has also changed and people can then investigate the change further. You can use fixity checking in a cloud service during upload, download and storage but it is worthwhile knowing what the original checksum for your content is.
The National Library of Scotland has been creating and recording SHA-1 and MD5 checksums for its digital content since 2013. This means that we already had checksums for all of the files that we uploaded to our cloud provider on the project - Edinburgh Parallel Computing Centre.
The iRODS data management software that the project uses to power its cloud services provides an option to undertake a fixity check during upload and download. It creates a checksum of your local file and compares this with the copy in iRODS. A typical upload command looks like this:
iput -K -T -f $pathOfFileToUpload $pathOfFileInIrods
The inclusion of the –K option in the command turns on fixity checking during uploading or downloading. Simple!
When the files are uploaded to iRODS a file entry with the checksum value is added to an iRODS catalogue that helps manage the content. So in addition to the check during upload we queried the catalogue as soon as the file was uploaded to obtain the checksum and compare it with the value in our local database – a double-check using two different methods. The command to query the iRODS catalogue looks like this:
iquest “SELECT COLL_NAME, DATA_NAME, DATA_CHECKSUM WHERE DATA_NAME = ‘$fileName’ AND COLL_NAME = ‘$pathOfIrodsFolderContainingTheFile’”
And will return information that includes:
DATA_CHECKSUM = 38e38626f6cc6fb63d8e784f71f3d886
In addition, iRODS provides a simple way for the user to force the recreation of the checksum for files stored in iRODS and then update its catalogue using the following command:
ichksum –f $pathOfFileInIrods
In Ubuntu’s terminal window (like the Windows command prompt) you will see:
123.tif 38e38623f6cc6fb63d8e784f71f3d886
Total checksum performed = 1, Failed checksum = 0
The iput, iquest, ichksum and iget (for downloading) commands can be applied to individual files, or individual folders containing multiple files and it is easy to send the information returned to a text file as a report that you can parse and integrate into automated workflows.
But how do we know if the checksum tools and information are accurate? To test this we uploaded a file with a known checksum value and obtained this from iRODS. EPCC staff then altered the file directly on the file system in a controlled way so that this modified file had a known checksum value. Finally we forced iRODS to recalculate the checksum and report it back. The value was updated and matched the expected value of the modified file.
Can fixity checks happen faster in the cloud than the local checks?
Our aim is to process the digital content in the cloud where it is stored and return a few small files that contain the results of the processing, rather than downloading the digital content locally and having to deal with the additional download costs, time and network bandwidth that comes with that approach. Fundamentally the speed of fixity checks is related to the algorithms used, the hardware available to you and how close the data is to the processing. Some commercial cloud providers offer compute as a service (CaaS) that allow you to undertake processing in the cloud and select more resources to undertake the processing at extra cost.
With their different technical infrastructure could the EPCC cloud service beat the National Library of Scotland’s local fixity checks?
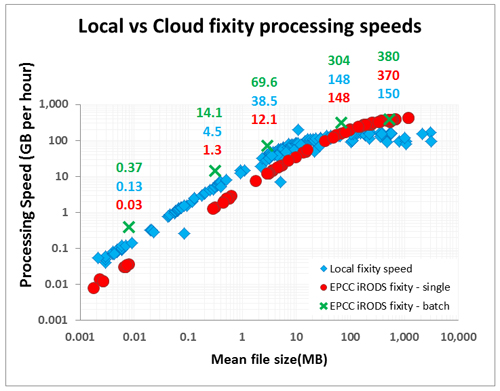
Figure 1. A comparison of fixity processing speeds for different file sizes using three techniques: Local processing since 2015 at the National Library of Scotland (blue); EPCC iRODS single file (red); EPCC iRODS batch.
Initially we undertook fixity checks by forcing the fixity check for a single file, querying iRODS to return the checksum value and then comparing it to the value stored in our local database. For files less than around 20MB in size the cloud was slower than what we do locally. For files above this size the cloud was faster. We speculated that checking single files one by one introduced a processing overhead and so we changed our technique to fixity check a whole folder, query iRODS to return the checksum values in one report for the whole folder, and then compare them with our local database. This approach improved fixity processing speed for all file sizes beating our local processing by a factor of roughly 2-3. With the composition of files the Library holds we can envisage being able to fixity check around 600TB of data per year using this approach and this could improve further with parallel processing.
Have any of the files in the cloud service changed undesirably?
Of 1,133,837 files checked 23 were problematic. 21 of these were temporary errors that could be overcome by checking the file again. 2 had genuinely different checksums. Of these one had a file size of zero bytes, but unfortunately, because it was part of our first test batch and was not logged we cannot confirm whether our local pre-upload copy was faulty or if this was an iRODS issue. The second file related to a test file where we intentionally inserted additional data directly through the file system to demonstrate that iRODS force checksum functionality worked (which it did).
How do you download and is it reliable?
If you are using the cloud to replace all of your local storage then at some point in the future you are likely to need to download it from one cloud provider to pass to another. If you are looking at the cloud as providing a back-up copy of your local data then you want to know that you can get it back out in the event of a fire, ransom-ware, or accidental deletions or modifications by staff.
Downloading from iRODS is simple. Like the fixity commands you can download single files or a whole folder of them (optionally including subfolders), and like before you can include the –k option to undertake a fixity check during download:
$ iget –k –r $pathOfIrodsFolderContainingTheFile
Of the 24 test batches, equivalent to 24 folders containing 433,133 files totalling 2.75TB, one batch was restarted and two reported a “No such file or directory” error, although none of the files were skipped and all were downloaded.
How quickly can we download digital content from the cloud service?
Ideally you want to know what the download speeds are likely to be from the range of cloud services on offer so that you can present the costs and benefits of such services to your organisation’s budget holders and policy makers.
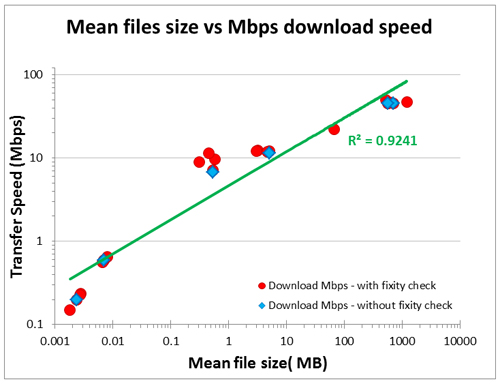
Figure 2: An analysis of the file size in a batch and transfer speed indicates that the smaller the files in the batch, the slower the download speed and vice versa.
As in our previous Cloudy Culture report on uploading we see speeds that are a lot lower than we would expect from the 1Gbps JANET network connection between the Library and EPCC acting as our cloud service provider. The maximum download speed is around 50 megabits per second for a folder of our largest files. The slowest is around 0.15 megabits per second for a folder of our smallest files. Removing the fixity check during download made no obvious difference. At this pace and using this method we would expect to download around 50TB per year. It is possible that there is some limitation on our iRODS set-up and that download speeds could be higher, as with the upload tests in our previous report, if we skipped iRODS and used a standard web API instead.
Conclusions
File fixity
iRODS data management software offers great file fixity functionality that is easy to employ and covers fixity during upload, download and storage. What’s more fixity checks can be undertaken in the cloud so customers don’t have to download their content to check it. This avoids download costs (normally the largest chargeable cost for cheap cloud storage providers) and the consumption of staff time and network bandwidth. In our tests the speed of fixity checking would allow the cloud to replace this local activity, or supplement it and reduce the overall risk of data loss by actively checking the health of 2 copies of the data.
In our project it was easy to validate that changes to files managed by iRODS were picked up by its fixity checking tools. This provides trust in a way that is not offered by current commercial cloud services.
A way forward for more transparent cloud storage services
It is widely recognised that those with a mandate to preserve digital culture, commercial assets and research data have to demonstrate that the data they care for does not unintentionally change over time. There is a commercial opportunity for cloud storage providers to share the file fixity information that they routinely generate with their customers at a price point that is attractively cheaper than the costs for the customer to download and fixity check the data themselves. This is a win-win, but has 3 requirements:
- The cloud provider is open about the frequency and nature of the checks so that the customer knows which cloud providers to engage with. Could the cloud provider enhance their offering at additional cost?
- The cloud provider can supply information as a report or API request such as which files were checked, what method was used, and when were they checked.
- The cloud provider has a test area for customers that allow the customer to produce reports either side of an intentional change to a file stored by the cloud provider. This provides reassurance to the customer (and gains trust) that the file checking tools and associated reports work and can be used by the customer.
Downloads
Of great concern is the download speed. We shortly expect to have to store 500TB of data per year and if we used the cloud service described here then it is likely to take 10 years to download a year’s worth of content. In this case it is clear that the cloud does not provide a suitable solution for large scale data loss. It would, however, offer a cheap and fast enough means to replace smaller quantities of files e.g. to help restore a small project that was accidentally deleted or modified, or replace the occasional corrupt file. Download speeds could be improved in several ways including:
- The data that you want is sent to you on hard-drives (“sneaker mail”). Check if your cloud service provider offers this, how you can cherry pick the data you need, and understand the associated costs.
- Files can be packaged in blocks or wrappers (like zip files) before or during upload so that the cloud only has to deal with large “files”. This means that upload and download is much quicker but it does require additional data preparation and file management locally. Fortunately some cloud service providers offer hardware appliances that can undertake some of this for you.
Without further validation of commercial cloud services the National Library of Scotland will have to exclude the use of internet downloads from cloud storage for anything more than 50TB to a) cover the risk of large scale data loss, or b) as a means of moving the data to other forms of storage or cloud providers.
Final thoughts
As we move towards the end of the project our expectations and requirements for the cloud are crystallising and we can begin to plan for commercial trials beyond the safety of the Cloudy Culture project. In our final report due around the end of the summer 2017, we will cover two important preservation considerations: running preservation tools in the cloud, and costs.