








































































































































Steve Daly is Head of Technology for BBC Archives.
At the BBC Archive we deal with a large variety of different multi-media assets, from physical video and audio tapes through to disk and cloud-based storage. Our highest-quality, uncompressed master video files are generally stored on LTO data tape, with copies in multiple locations.
This means we’re managing tens of thousands of data tapes and, whilst all these are heavily tracked in our warehouse and data management systems, not all the other data tapes that come into our possession have been looked-after quite so well.
Where we receive or inherit tapes created outside our own operations it can sometimes be difficult to be sure of the exact provenance of the contents and how best to read and understand them. We want to make sure we’re not creating issues like this for future users of our own data tapes, so we take a few additional steps to ensure the long-term life of our content.
README
Firstly, for every single data tape we write we make sure that we store a README file on it.
This is a simple text file which describes how the content on the tape came to exist; why it was written to tape; and any information we want to pass on to future users of the content.
For example, we might explain that some content is only being written as a temporary backup of some work-in-progress, or instead that these are the final archive masters of a particular collection. And we might add detail of technical commands needed to process or use the files in future.
Although all this knowledge is also held in our database systems, from our own experience we worry that over a long time-period the tapes could become separated from the data about them so we always try to ensure they are self-describing.
Many of our tapes are written by automated systems, for example where we migrate between generations of data tape (e.g. LTO3 to LTO7) and we take some further steps in these cases;
Boilerplate
We write a ‘boilerplate’ text file to each tape with a full history of the project that created it, including as much detail as we can and writing in a way that doesn’t assume any current knowledge of our operations. We use Markdown for this, to combine universal readability with some optional nice formatting.
Files
We list all the file-types on each tape and explain where the files came from and their purpose

Format Documentation
For the more esoteric formats, we include the complete file format specification (in PDF-A of course)

Data
We include a complete data set (as CSV) of the whole project, not just for the files on the tape, so that you can see where this subset sits in context.
Source Code
The BBC are heavy users and creators of open-source software, and on each tape we put:
- A complete copy of the source code which was used to create the files on the tape
- Source code for software that could be used to replay and re-use these files
Videos
Being a content-creation organisation, we thought it appropriate to make some videos about the project – interviewing a selection of people involved to explain the background and the workflows and processes involved.

As a reminder, all of the additional material I describe here is added to every single data tape we make. It adds about 1GB to each 6000GB tape we make, so only an 0.02% overhead.
We currently write LTFS tapes for situations like this so are comfortable with future readability but for more complex format (e.g. tar) we make sure that a valid restore command is included with each tape. I’ve seen another organisation laser-etch this command onto each of their tapes, but we haven’t gone that far (yet).
I like to think of this like the plaque on the side of the Pioneer spacecraft.
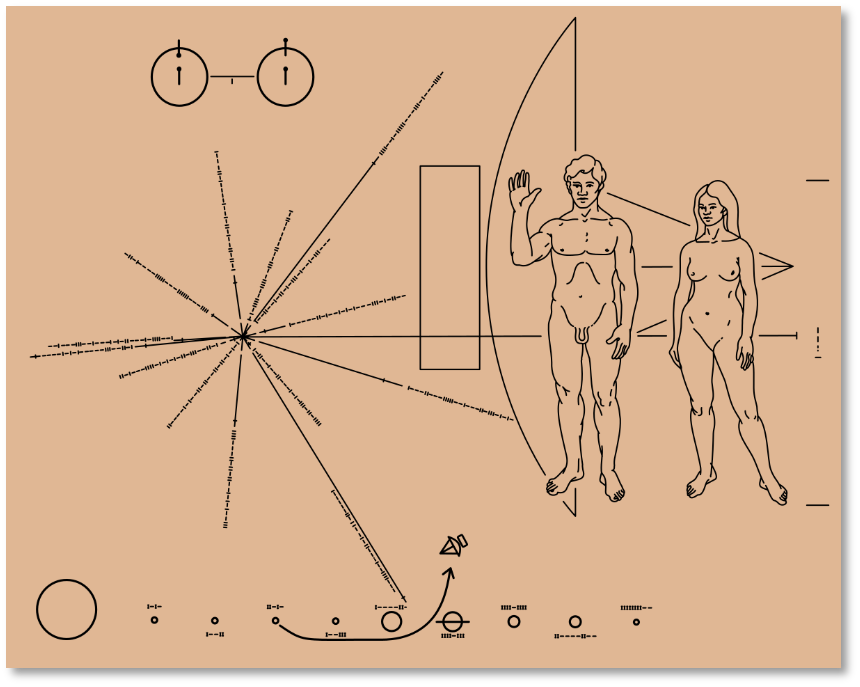
If one of these data tapes was separated from the herd, or if some future lifeform stumbled across these tapes, we hope that they would be well-placed to get the very best out of them.