
Roxana Popistasu is Digital Preservation Coordinator at Bibliothèque nationale de Luxembourg
“In digital preservation, identification of digital content is essential”, say A. Dappert and A. Farquhar in their iPRES 2017 article Permanence of the Scholarly Record: Persistent Identification and Digital Preservation – A Roadmap. The same idea appeared in the introduction of Robert E. Kahn’s keynote at iPRES 2016:

https://twitter.com/RoxPoNinja/status/782850754059132929
At the National Library of Luxembourg (BnL), we agree unequivocally: we cannot preserve and provide access to our national heritage without taking into account the reliable and sustainable identification of our digital resources. But how do we do that? What is the “best” persistent identifier (PID) system? Are there best practices when it comes to persistent identification? These are some of the questions we set out to answer at the start of our journey into finding the right PID system.
As interoperability and reuse are important aspects of the persistent identifier infrastructure, the National library decided from the beginning to go with an established identifier schema. The first step was analysing some of the existing schemas and current implementations: ARK, DOI, Handle, PURL and URN: NBN. Taking into account the specific needs of the BnL and of other resource producers that might be interested in such a system, we chose ARK (Archival Resource Key), created and maintained by California Digital Library. ARKs are URLs designed to support long-term access to information objects and they identify objects of all types: physical (books, DVDs, monuments etc.), digital (documents, images, e-books etc.) or even immaterial (concepts, vocabulary terms etc.).
A persistent identifier infrastructure encompasses more than just the technical aspects of identifier attribution (and maybe resolution):

https://twitter.com/An_Old_Hand/status/783926910724210688
Because of that, while evaluating the existing implementations for persistent identifiers, we tried to look not just at the technical aspects, but also at policies, interoperability and, most importantly, at lessons learned. Articles like Identifiers for the 21st century: How to design, provision, and reuse persistent identifiers to maximize utility and impact of life science data and 20 Years of Persistent Identifiers – Which Systems are Here to Stay? or David Rosenthal’s Bad Identifiers blogpost summarize some of these points very well.
As a result, here are some of the decisions the BnL took when implementing ARK as a persistent identifier service:
- Opacity: Attributed identifiers will not contain, as far as possible, any easily recognizable semantic information; this helps to facilitate their use regardless of a time or place context. In addition, the identifiers contain a control character that guarantees them against single-character errors and transposition errors.
- Reassignment: No identifier will be reassigned or deleted: once a link between an identifier and an object has been published, this link must be considered as unique, and for an indefinite duration. If a resource is deleted, a minimal description of the resource will be provided, mentioning that is was deleted (“tombstone”).
- Metadata: A brief metadata record will be provided through ARK inflections.
While https://persist.lu/ark:/70795/62mkgv/ will point to the digital resource, https://persist.lu/ark:/70795/62mkgv/? will provide the metadata about the object:

- Persistence (policy) statement: A maintenance commitment from the PID service will be provided through ARK inflections. https://persist.lu/ark:/70795/62mkgv/?? will provide the following information:

The policy statement uses the draft vocabulary for making “persistence statements” presented by John Kunze & others in Persistence Statements: Describing Digital Stickiness. As the work continues on this vocabulary, the BnL policy is also subject to change.
- Transparency: BnL publishes exhaustive documentation about the structure of the PID system, the definitions used, data models, rules and technologies, as well as the policies for assignment and resolution.
- Collaboration: As with other projects, the BnL immediately took the decision to collaborate with other national and international institutions on the development and interoperability of persistent identifiers in general and of ARK in particular (ARKs in the Open is one of the projects we participate in).
However, our work is not finished. Some of the aspects we are currently working on are listed below:
- High availability (redundancy) of the PID service
- Offer the PID infrastructure as a service to other interested organizations in Luxembourg
- Analyse the possibility of adopting
- Signposting, as described by Herbert Van de Sompel and Michael L. Nelson, in order to improve the automatic crawls, machine-harvesting and machine-interpretation of the digital record
- PREMIS for the metadata associated with PIDs, as proposed by A. Dappert and A. Farquhar (Permanence of the Scholarly Record: Persistent Identification and Digital Preservation – A Roadmap)
At the end of the day, we should not forget the most important point: persistence is first and foremost an organisational commitment. The National Library made a pledge to provide the technical infrastructure for persistent identifiers (in terms of both attribution and resolution), but also to continually adapt in order to guarantee the sustainability and resilience of the system in the long term.
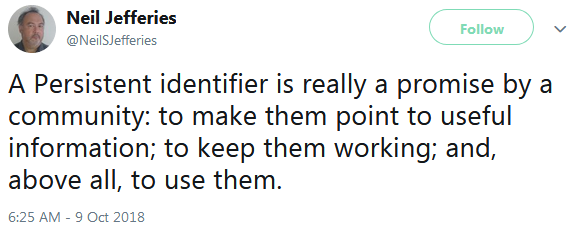
https://twitter.com/NeilSJefferies/status/1049652195673681922