








































































































































Paul Young is Digital Preservation Specialist/Researcher at the National Archives UK
What’s the problem?
Determining reliable dates for digital records can be a source of frustration, especially when confronted with a large volume of digital files with dates that are obviously incorrect, such as why your Microsoft Word Document 1997 version dates from 1st January 1970.
Dates are very important for The National Archives in particular as we look to transfer records from departments under the 20-year rule of the Public Record Act. When these dates are unknown or obviously incorrect, we cannot be sure if a department is in compliance with the Act.
The National Archives uses the ‘date last modified’ generated by the file system, and extracted via DROID, as the standard ‘go to’ date to populate the official ‘date’ entry in our catalogue. After seeing several collections and scenarios where the ‘date last modified’ did not provide an accurate date for the file we have been doing a bit of investigation of other methods for extracting accurate dates for born-digital records.
The ‘date last modified’ field was originally chosen because it was deemed the most reliable out of the file system dates. Creation dates can change when copying files (often to after the last modified date). Sarah Mason’s blog nicely illustrates examples of when creation and modified dates change and there is also a white paper by the SANS institute which looks into how different file systems handle dates. As shown in Sarah’s blog even the date last modified is not immune to change, especially when uploading or downloading to cloud storage. Blogs by Jenny Mitcham and Ed Pinsent respectively on Google Drive and SharePoint also highlight some of the issues that can happen to dates when using these platforms.
As Ed points out, the best defence against date issues is to preserve the original file system metadata. This can be achieved using tools such as Teracopy or Robocopy when moving around file systems and by using appropriate tools and methods for migrating to cloud platforms. However, often for legacy material this happens too late and date metadata has already been corrupted or lost.
What to do?
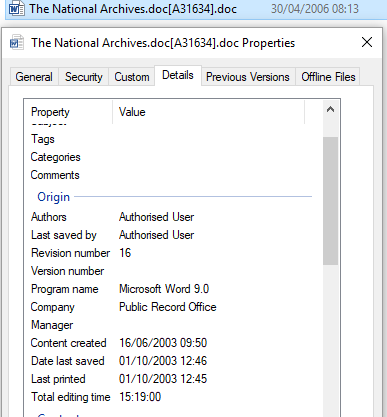
One solution we have been looking at is examining the date metadata that certain formats hold within themselves. Common formats such as doc, docx and pdf files all contain date metadata that can be more resilient than file system dates. If you click on the properties of a document and then go to ‘Details’ you can see some of the metadata held within the file, often with different dates to those displayed in Windows Explorer. One advantage of this metadata is that, unlike file system dates, these dates are held internally so any alteration would result in the checksum of the file changing.
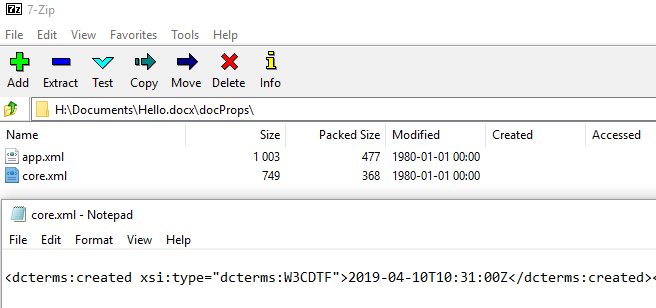
A good example of where this metadata is held can be seen by examining a docx file (based on Office Open XML), these are actually ZIP files containing XML and other data files. You can view these by either opening the file as an archive using 7-Zip or changing the extension to .zip. The metadata for the file properties are contained within an XML file called core.xml within the docProps section.
So we see that there is potentially useful metadata within these file types but how do we extract it for analysis? Well going back to Ed’s blog he used the tool Apache Tika, which is capable of extracting metadata from over a thousand different formats. It is an incredible tool for pulling out metadata (especially dates).
In looking for an easy way to use Tika over a batch collection of files I found Peter May’s blog around work done at a SPRUCE hackathon back in 2012. This uses a Python script to utilise Tika to scan folders of files and generate a CSV output of results.
Tinkering with Peter’s script, I updated it to Python 3 and a recent version of Tika, making use of new batch features included within Tika itself. You can view the updated script here along with instruction for use (it only needs you to input the directory to scan on prompt by script), I also have an executable version (without need of Python) please contact me if you would like a copy. This has allowed us to scan large collections of digital records and view the metadata that Tika has been able to collect.
Here’s one I made earlier
So how do we test this? Well, to find an example I did not have to go too far, looking at one of The National Archives first digital transfers (from ourselves covering our digital preservation and preservation departments). The series information says the material was accumulated from 2003-2008. Examining the dates in detail however shows that out of the 1454 files the majority (1447) date from a small period between the 14th April and the 03rd May 2006. Something seems off! Looking at the series information I can see that the date last modified generated by the EDRMS was used to populate the date information, I can also see that from 2005-2006 there was some departmental changes, suggesting that a potential moving of data at that time may be the cause of the date issue.
Taking a (very) small subset (1pdf, 3 word docs) for illustrative purposes we can review them. Running Tika and looking at the results we can see a range of creation and modified dates (taken from internal format metadata) all from 2003, rather than 2006. Which is right? Looking at one of the docs ‘The National Archives.doc[A31634].doc’ we can open this and see it is a paper on the guidelines for the conservation of paper manuscripts, dated September 2003. So the 2006 date seems a little off. Tika gives us a modified date of October 2003 (not bad) and a creation date of June 2003. Another example ‘Technical Paper 1 - Preservation Metadata 0a[A659920].doc’, when you open this you can see it is dated as 12 November 2003. Tika analysed the modified date as December 2003 and created as June 2003, so again modified is only one month off but a lot closer than 2006. Using Tika we should be able to extract more relevant dates for this series in an automated approach.
Problem solved?
We have had some success using Tika where transferring departments have had issues with file system metadata. One had lost relevant dates (to a fairly small collection) after uploading to Google Drive, with this Tika was able to extract modified dates which the department stated were accurate.
However, with another department that had lost file system dates due to migration the department felt that the Tika results were around 50% accurate, after viewing some files. Why is this? Well, it could be for a few reasons. One option, as Ed noted in his SharePoint blog, is format conversion. Many of the records in that collection were a mix of doc and docx files, when you update a doc file to the newer docx you seem to lose the original metadata stored in that file.
After reading Ed and Jenny’s blogs and the tests they did on how SharePoint and Google Drive affected dates, I also wanted to see what data Tika could grab from a doc or docx file in Google Drive that had been converted to the Google Docs format and then downloaded as a docx. Unfortunately, the docx version that Google downloads does not seem to have a ‘docProps’ section (mentioned above), which is where Tika is looking for metadata, so returns are minimal. Google are rolling out a feature which allows Microsoft Office Docs to be edited in Google Docs without having to be converted to the native data format, I was able to try this and for these it does retain the ‘docProps’ section and metadata (and even seems to retain date modified when converting doc files to docx).
The internal date metadata also relies on the file system metadata at the time being reliable, as that is where it picks up the dates originally. Going back to my example at the start of a Word Document dated from 1970, if the file system has an error and restarts its clock it will return to the Epoch time for the operating system (Unix Epoch is 1st January 1970). An example of an issue caused by the Epoch date is when people were congratulated for being friends on Facebook for 46 years. Another date which crops up in Windows environments is the DOS Epoch of the 1st January 1980 (see my 7-Zip screenshot earlier in the blog for an example of this).
The above examples show that even the internal metadata cannot be relied on completely, it depends on how it was generated and how the data has been managed. There is also the fact that this method only works for formats which hold inherent date metadata, fortunately for The National Archives many of the formats we currently receive (doc, docx, pdf, msg) fit into this category, but it won’t be the case for all collections.
What else to do?
So identifying (more) accurate metadata will not solve everything …
What else can we do? Well, in previous examples opening the files themselves and having a look at the date allowed verification. Unfortunately that method does not scale well, in a collection of 3 million records you would not really want to open them all and scan for dates. Another method I wanted to test was ways to extract dates from the text of records.
I haven’t explored this option fully yet but have had tried out a couple of methods. First by extracting the text using Tika, then using two Python date applications, the first datefinder uses regex to identify date entities and normalise them into ISO 8601 date format. I also had a go with SUTime, part of the Stanford Core NLP, using its python wrapper, this outputs results showing the original dates as well as converting to ISO 8601.
Results from both were interesting, though a little confusing. Both applications generally picked up accurate dates mentioned in text; though datefinder in particular also picks up a lot of false returns. Identifying which are accurate dates would still require additional work.

Both applications assume text is not historical so that when identifying text such as ‘Sunday’ it gives us the date for next Sunday, which meant that both returned a lot of 2019 dates. Also if the document references a lot of dates (such as the paper on preservation of manuscripts) this can create very wide date range, this is potentially useful for adding context to the content of the record but not for dating it.
There is also the fact that both applications as default assume dates are written in US date format (mm/dd/yyyy) when they normalise the dates into ISO 8601.
While not without issues I think the approach is worthy of further investigation as a way to provide additional context to documents containing text.
Anything else?
The more I have looked into dating born-digital records the more it has felt like just scratching at the surface, I believe it will not be a one size fits all solution and that a multitude of options could be brought to bear. Understanding some history in the management and type of records can help detemine the most appropriate course of action and metadata to use.
I believe it will become harder to determine a single date for a digital record, by exposing a range of date metadata it would allow us to examine the reliability of the metadata and its source and the probability of its accuracy. As well as determing dates of compliance for tranfer to The National Archives it can also provide more accurate date ranges to researchers.