
Sheila Morrissey is Senior Researcher at Ithaka S+R, based in New York
If there’s one thing digital preservationists understand, it’s the importance of continual investment in infrastructure. That includes our own technical infrastructure – the systems we rely on to collect and manage and deliver digital objects over the very long term.
On the first World Digital Preservation Day, we were just at the mid-point of a two-year project to rebuild Portico’s technical preservation infrastructure, pretty much from the ground up. At the end of September of this year, we closed out our “NextGen” project as scheduled.
As we noted in last year’s WDPD day of blogging, a big motivation for our “gut rehab” project was the need to grapple with issues of scale – with geometric growth across pretty nearly every measure of content streaming into the Portico archive:
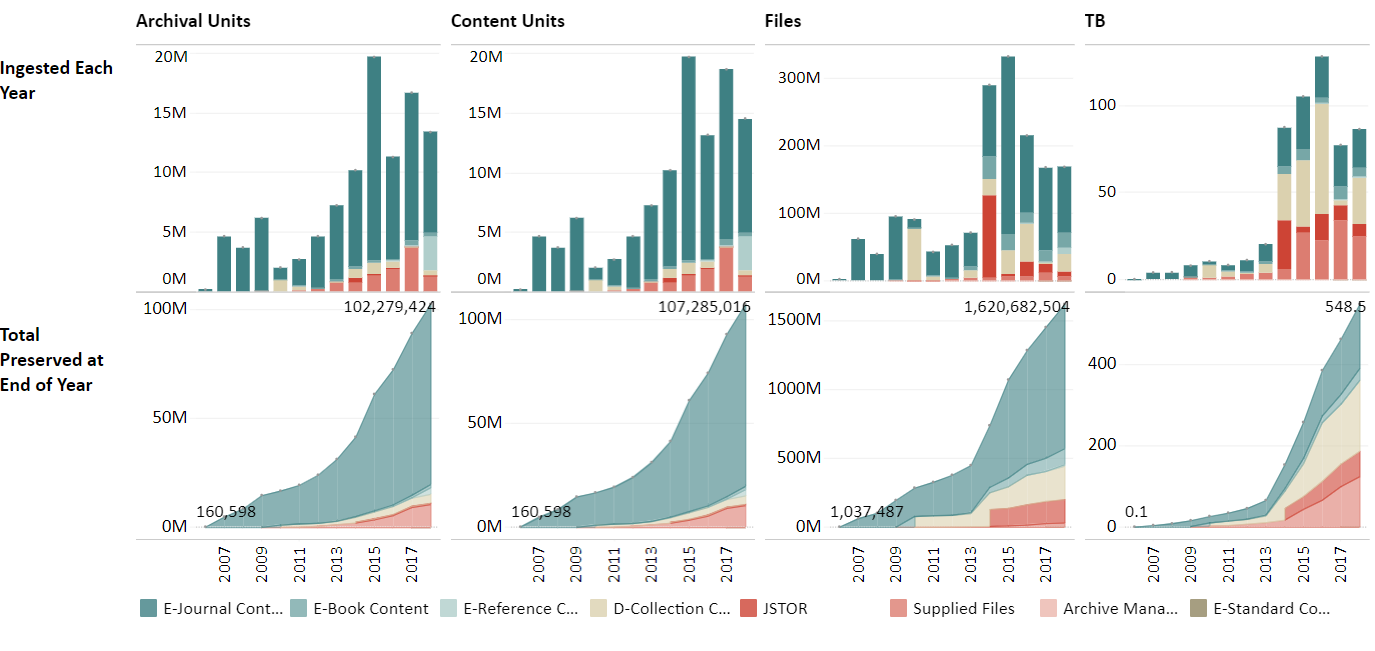 Over 100 million archival units, over 1.6 billion files, over half a petabyte of content in each archive replica, and, more importantly, those steeply curving growth rates – all were telling us we had to find ways to process, ingest, store, and manage more and more content, at less and less cost per content unit, in order to remain a sustainable preservation service for the academic library and scholarly publishing communities.
Over 100 million archival units, over 1.6 billion files, over half a petabyte of content in each archive replica, and, more importantly, those steeply curving growth rates – all were telling us we had to find ways to process, ingest, store, and manage more and more content, at less and less cost per content unit, in order to remain a sustainable preservation service for the academic library and scholarly publishing communities.
In urging the importance of digital preservation, we often focus on the risks to long-term use of digital artifacts caused by rapid rate of change in both the hardware and software that mediate the rendering of those objects. So it was real treat to take advantage of the upside of those rapid changes, in the service of digital preservation itself.
The first use we were able to make of those developments – and of the shared experienced of others in digital preservation grappling with the same problems – was to move from vertical to horizontal scaling. We were straining the limits, both of the relational databases caching operational information, and of read-write bottlenecks in our storage area networks. So we broke out our “monolithic” system into self-contained processing and archive “pods”:
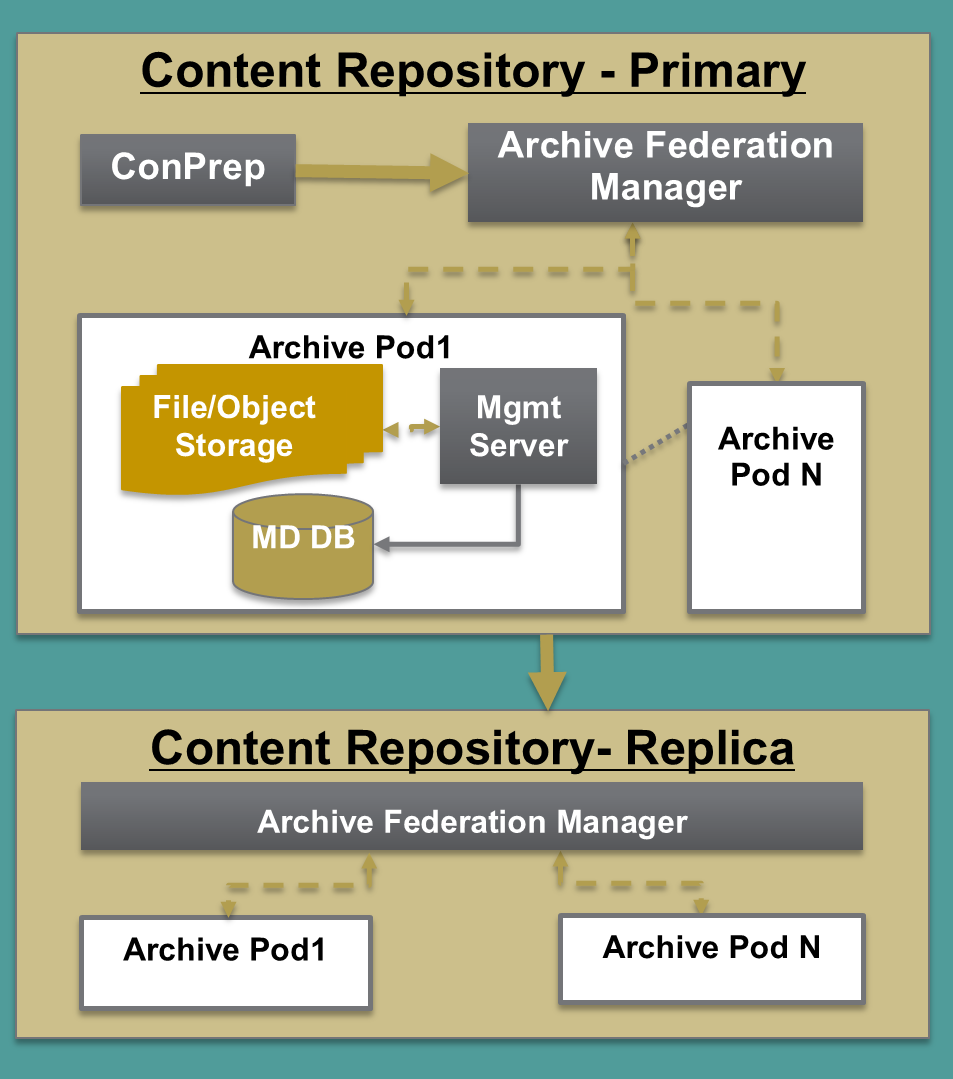
As we made that shift and began reviewing hardware choices, we took the occasion to do an analysis and comparison of both costs and other non-cost criteria in both data center and cloud-based platforms. In our case, we found there was an overwhelming cost advantage to remaining in the data center (though we do replicate some content to a commercial cloud).
Because each archive “pod” is self-managing (handling such matters as periodic fixity checking), we were able to add policy-based archive storage and replication as a new feature to the archive. This makes it possible automatically to assign the number and type of archive copies, as well as the type of storage for each copy, based on criteria as fine-grained as an individual content item itself, simply through specifying that choice in a configuration file. It also has made it possible for Portico to establish a live replica of its archive with our long-time preservation partners, the National Library of the Netherlands (KB).
The shift to the new horizontally-scalable architecture is already paying off. We are seeing much better performance in all our processes. This includes a four-fold increase in throughput of content processing, as well as order-of magnitude improvements in archive analytics queries and reports and in updates to the Portico public-facing dashboard. We also expect to see both lower and more predictable hardware costs for Portico in the coming years.
Another key component of the NextGen architecture are new analytics services, intended to provide us with an integrated view into and across all our systems, processes, and content. The new analytics data and processes are used automate the insurance of storage policy consistency, to trigger replication, to report on fixity failure, and to trigger the disposition of redundant processing copies of content once it has been archived and replicated. These services cache important content-processing event data, as well as metadata about the content in the archive, and provide real-time monitoring of our applications.
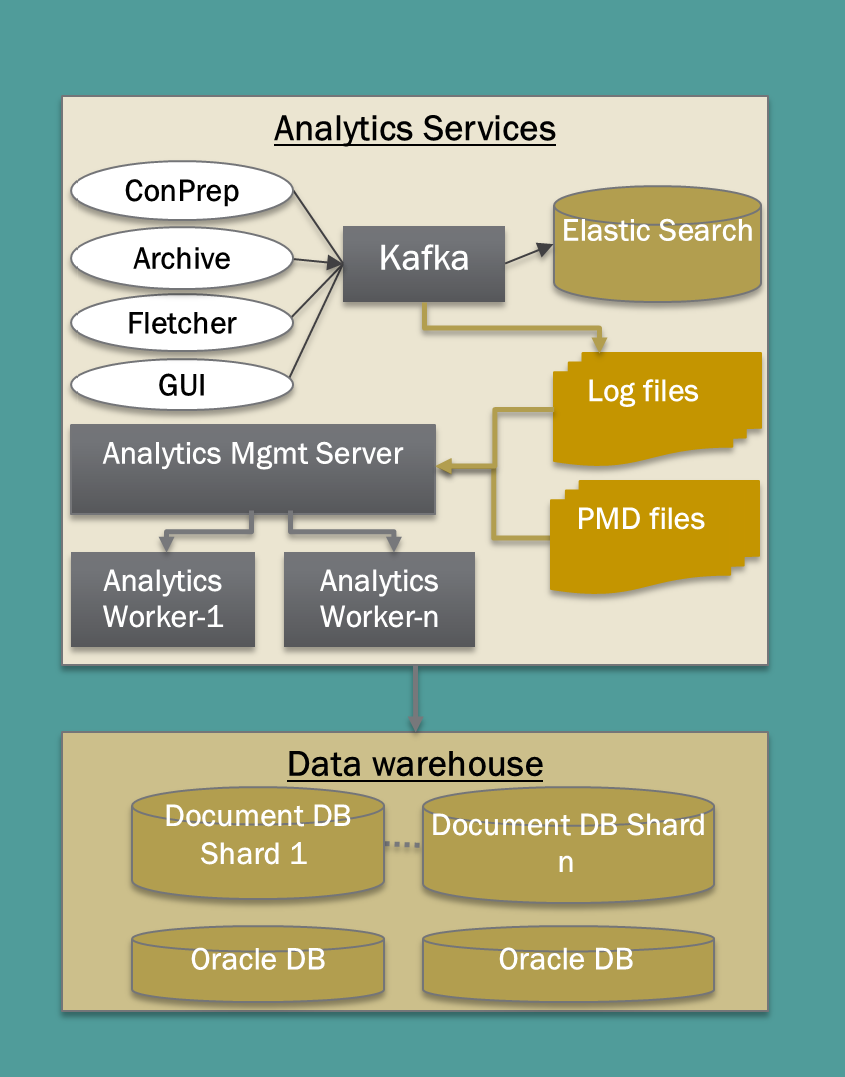
These new analytics services provide a framework for the next project we are undertaking here at Portico, which is called “Straight to Ingest” – S2I.
Not all content submitted to Portico is as "perfect" as we might like -- it could be missing referenced images, or have defective descriptive metadata, for example. Rather than leave that content sitting in the ingest queue until its creator has an opportunity to "repair" it - we'd like to get it into the archive as rapidly as possible, where it will be replicated, and have regular consistency checks performed on it, and so on. And, with new analytics information, we hope to be able to focus our resources -- people-- on fixing what can be fixed, and focus our efforts on the most egregious problems that impact the usability of the content in our care.
If you are interested, you can learn more about both the NextGen architecture and Portico’s plans for S2I from the Notes page and slides by Portico’s Vinay Cheruku and Amy Kirchhoff, as part of a workshop at iPRES 2018.
And, of course, watch for next year’s WDPD!