
Nick Thieberger works for the Pacific and Regional Archive for Digital Sources in Endangered Cultures (PARADISEC) and the University of Melbourne. Nick won the Research and Innovation Award at the Digital Preservation Awards of 2024.
“Those who do not see themselves reflected in national heritage are excluded from it."
Stuart Hall*
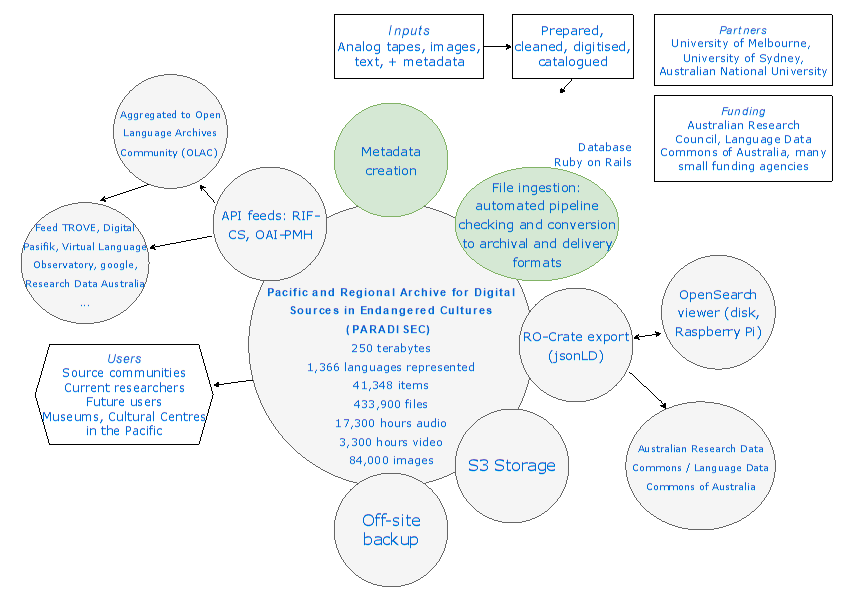
The Pacific and Regional Archive for Digital Sources in Endangered Cultures (PARADISEC) is an exemplary research repository, primarily for records in ‘small’ or ‘under-resourced’ languages, records that would otherwise have no archival home. These records include manuscripts, media recordings (with transcripts where possible), dictionaries and so on. Many are the result of fieldwork by an outsider researcher in a small community. For some of these languages, this is the only material in them available on the web.
PARADISEC demonstrates end-to-end training and assistance with creation of citable research data and metadata, longterm curation, and APIs to maximise findability. It shows how a relatively low-tech Australian DIY [1] solution can be world-leading. It uses standard metadata terms and conforms to relevant international standards, allowing its catalog to be harvested by the Open Language Archives Community (OLAC), TROVE, Research Data Australia, Digital Pasifik, and google, among others.
PARADISEC holds 240 terabytes of material in 1,366 languages, some going back to the 1950s. It continues to accession recordings and images from current researchers. It works with the Vanuatu Cultural Centre and Solomon Islands National Museum, and the Universities of French Polynesia and New Caledonia to support similar work there. Based at the Universities of Melbourne, Sydney, and the ANU, it is currently also supported by the NCRIS-funded Language Data Commons of Australia [https://www.ldaca.edu.au]. This work has also been funded from a range of different sources, including ARC LIEF, Future Fellowship, Centre of Excellence, and international funding bodies that provide project based funding.
Originally designed to digitise and preserve recordings made in the past that were at risk of loss, PARADISEC has now moved on to accept born-digital research outputs, providing citable forms of primary data for use on current research. Each item is licensed for reuse, and some can be held as closed or even hidden items. The responsive platform we have built allows us to close an item immediately if need arises, for example, in some communities, in the case of the death of the speaker may require their recording to be closed for a period.
The PARADISEC collection is stored in Amazon S3 [2] provided by the University of Sydney, and is written as Research-Object Crate (RO-Crate), conforming to the Australian Research Data Commons standard, to ensure longevity, as each item is stored together with its RO-Crate file (in jsonLD). This allows us to take arbitrary objects from the collection and to write a catalog of just that selection by harvesting metadata from the standard structure of the RO-Crate. We can then deliver this subcollection on hard disks or Raspberry Pi for local wifi transmission.
PARADISEC is an exemplar of a research repository that provides a home for research material, a base for future research based on fixed and citable material, and a public-facing resource that is maximally findable by the small communities in the Pacific that have internet access and can now find online records in their own languages.
In 2024, PARADISEC won the highly competitive Digital Preservation Coalition Award for Research and Innovation.
*Attributed and cited in many places, but I can’t find the reference
1. Schematic of the PARADISEC collection
[1] Niamh Moore, Nikki Dunne, Martina Karels, and Mary Hanlon, ‘Towards an Inventive Ethics of Carefull Risk: Unsettling Research through DIY Academic Archiving’, Australian Feminist Studies, vol. 36, no. 108, p. 184. https://doi.org/10.1080/08164649.2021.2018991.
[2] To pre-empt queries about privacy, our S3 storage is within Australia and Amazon states that they do not use our data in any way. S3 storage costs us about a tenth of previous storage cost which frees up funds for other work. We have opted-out of Amazon using any of our material.