
Teresa Soleau is Digital Preservation Manager and Alexis Adkins is Institutional Archivist. They work at the J. Paul Getty Trust.
As one of the newest members of the DPC we are thrilled to start working more closely with others in the digital preservation community, hearing about their work and sharing ours. As a first step in that direction, we’re going to share with you some web archiving work we’ve done in the past year. At Getty we don’t have a specific person dedicated to web archiving so the work is done collaboratively between staff in Institutional Records and Archives and Getty Digital.
This year we have codified some of our existing practices into a Web Archives Collecting Policy. While we’d been capturing our site using Archive-It since 2017, it was done using bits of “extra” time from a variety of staff and when issues were encountered they easily fell to the side as other priorities arose. With our current web redesign process we needed to get a bit more formal.
Drafting this policy has been a great way for us to refine and clarify our goals and processes. Sharing it with program managers, content producers for getty.edu and others throughout the institution has given visibility to this work that is sometimes taken for granted as a given when, as anyone who has done web archiving knows, it needs to be deliberate and can be time consuming if it’s going to be useful. In the policy, we outline the different types of web content we capture, what’s to be expected in terms of fidelity, web properties that are out of scope, the responsibilities of those involved in this work, and technical choices that have been made about crawl scoping.
As mentioned above, one of the motivations for us to codify our web archiving work is our ongoing website redesign. With significant changes to the underlying technology as well as the strategy and purpose of the site, the redesign is much more than a face lift. As part of this work, a content audit was undertaken. Migrating pages to the new site requires a lot of effort, so hard decisions had to be made about what would not be carried forward. Of the approximately 22,000 (!!) existing pages audited—a fraction of the even larger total—40% of them were designated to be removed from the site - either deleted altogether or archived before deletion. Luckily, through crawling the site, we can preserve and still provide access to the information even after it’s removed. This project has required us to communicate the importance of a complex and sometimes technical process to stakeholders across the institution who are understandably focused on moving forward, not on addressing the issues inherent in a website that has outdated, broken or orphaned content. Web archiving work isn’t the sexiest, but everyone agrees that a commitment to ongoing stewardship of the content on our site will provide a more sustainable product and a better experience for our users.
Getty.edu before redesign

Getty.edu after redesign
One of our more targeted web archiving projects has been Getty’s online exhibition Return to Palmyra. The site was launched in February 2021 and is a reimagining of Getty’s first ever online exhibition The Legacy of Ancient Palmyra. The earlier exhibition was launched in 2017 and features 18th century engravings and 19th century photographs of the ruins of the ancient caravan city that flourished in the 2nd and 3rd centuries CE and is located in modern-day Syria. The new exhibition includes the original content along with additional texts, an interview, enhanced features, and a classical Arabic translation of the full site making the exhibition accessible to a wider audience.
We quickly got to work crawling the new exhibition. As many web archivists can attest, the more dynamic and complex a web site, the more difficult it can be to get a full capture. Although web crawling software is powerful, it is always a few steps behind the latest web technologies. Our main difficulty with Return to Palmyra was with “playing back” embedded YouTube videos of lectures related to the exhibition and thumbnails of images in the Exhibition Checklist section.
We tried re-crawling the site, patching earlier crawls, tweaking our scoping rules, and pointing the crawler directly at the most troublesome urls. Archive-It staff offered us suggestions and were able to “look under the hood” and confirm that specific images were successfully captured, even if we couldn’t replay them in the Wayback Machine. Image replay issues were resolved by the new Python Wayback Machine, which Archive-it released in September 2021. Embedded YouTube videos still do not replay but this is a common issue with content hosted on third-party platforms and in this instance we can preserve the videos separately so we consider the capture adequate.
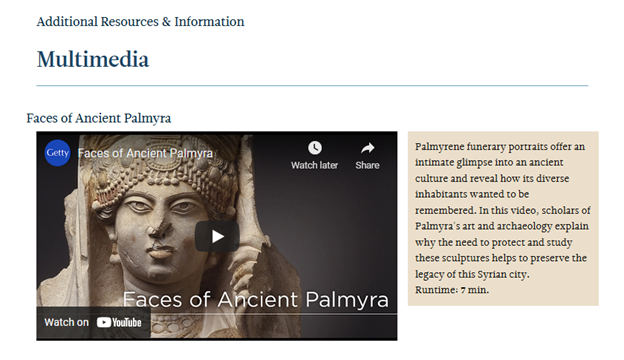
Embedded YouTube video on live Return to Palmyra website

Archive-It capture of embedded YouTube video on Return to Palmyra website
The projects we’ve described here have given us the opportunity to introduce web archiving to non-archives staff, hopefully making it more accessible and understandable. For the Palmyra project, we were able to review the capture in depth, but this won’t be possible for larger projects like the website redesign. We will need to rely both on content owners across the institution and hopefully find some automated ways to evaluate the crawls. There is always something keeping us on our toes as we work to preserve Getty’s web presence for future generations.