






































































































































Sonia Ranade and Alec Mulinder work for the UK National Archives
Thanks to your posts on this blog over the last two years, we have a really good understanding of what digital preservation is: we’re on a mission to send messages to the future. And we want those messages to be faithfully transmitted, to retain their meaning and to be useful for generations to come.
That’s a tall order, but fortunately, the digital preservation community is here to help. Our models give us a common frame of reference. The DPC handbook provides a knowledge base distilled from our collective experience. We have standards and certification schemes to help us benchmark our progress. So, we’re good to go, right?
Well, not quite. Our world is not static. Threats are constantly changing. Our resources and ability to deal with them change too and it’s not always easy to see what to do next. We all have a long list of good things to do, but the reality is that few of us will ever have the luxury of doing all of them. Even the best resourced archives must make choices about how and when to invest in digital preservation. And these are difficult decisions. Should we start with secure, reliable storage? Or it is more important to understand the file formats we’re dealing with? Is improving physical security likely to manage threats more effectively than implementing better auditing? Should we invest this year’s funding in staff training or use it to reduce the complexity of our systems? Maybe it's better to spread our resources thinly and try to do a little bit of everything?
We think the answers can only come from a better understanding of the risks to the preservation of our records in our environment. But that’s a lot harder than it sounds. At The National Archives, we’re tackling this challenge by trying to introduce a more structured approach to assessing digital preservation risks, so that risk management informs our day to day practice and isn’t ‘hidden’ behind a layer of standards, process and systems.
We’re aiming to create a new framework for managing digital preservation risk that:
- Describes and explains a complex and interdependent map of risk events, risk management actions and their impact on preservation outcomes.
- Lets us compare and prioritise very different types of threats to the digital archive with potential impact in different areas.
- Operates even where we have limited data or imperfect evidence.
And to do that, we are using a Bayesian approach to risk modelling. In brief, this is a statistical technique that is quantitative and underpinned by networks of cause and effect. One of its strengths is the potential to to explain and make predictions about our environment through combining observed data with hard won knowledge and experience. We know it has been successfully applied to risk management in other fields that are at least as complex as digital preservation, so it seems reasonable that we can apply it too.
A Bayesian approach is incremental. We don’t have to tackle the whole problem at once but can map out sub-networks within the problem domain, bringing these together gradually as our model evolves. That means we can start exploring the risks without having to tackle the full complexity of our preservation environments from the outset. And the sub networks (and sub networks below those...) are inherently modular, meaning that this effort could be shared.
Bayesian systems are built to accommodate environments that are dynamic and constantly evolving – just like digital preservation. Jim Smith a leading proponent from Warwick University uses the analogy of Lego, where you can re-purpose the individual bricks to build many different houses. In other words, the building blocks of a Bayesian network could be applied to map risk in different digital preservation environments, whether in UK archives or internationally. This ability to build across parallel systems (including analogous but different contexts from other domains) is very appealing. The approach could help the global digital preservation community to pool our understanding and make best use of our shared knowledge and experience.
On a practical level, a Bayesian approach means we can feed in hard data where we have it and use reasoned assumptions based on the judgement of experienced digital archivists where we don’t. The approach lets us go on to refine these judgements over time as our understanding develops.
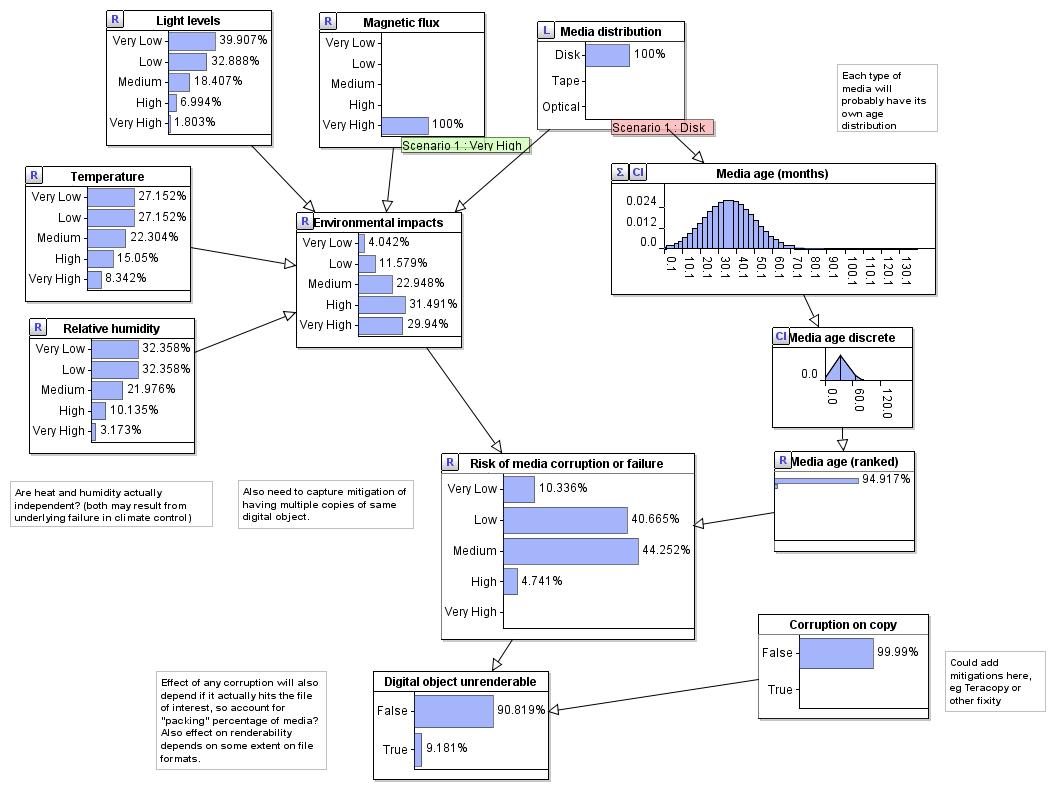
This generic setup shows at how a distribution of storage across different media with particular age profiles and potential different environmental conditions for storage
might over time give a risk that a digital object would not be renderable due to corruption whilst sitting in storage.
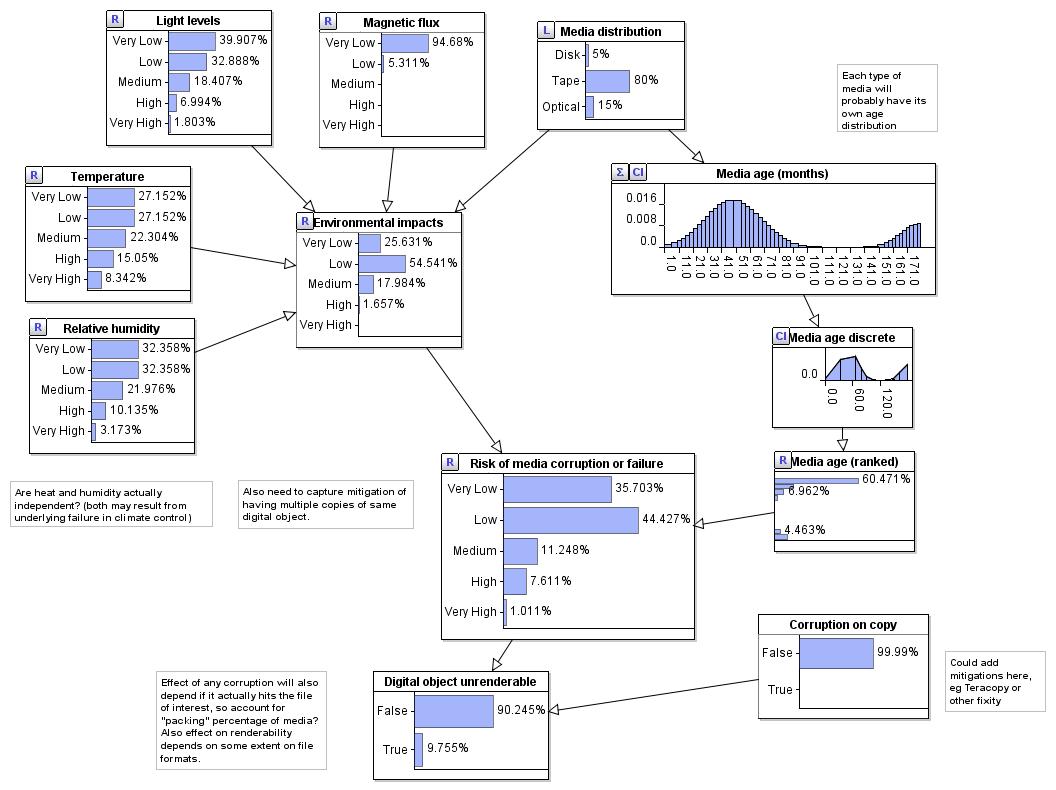
The same model illustrates how you can test different scenarios, deciding that you will only use disk storage,
and what would then happen if your disks were exposed to a very high levels of magnetic flux for some reason.
We think adopting a Bayesian risk model will help us make better decisions about how to invest our (limited) resources, for example, by helping us to more easily evaluate different preservation strategies or weigh up the impact of different risk mitigation options. It will give us the evidence we need to help communicate the impact of investing in digital preservation – and even highlight the consequences of under-investing!
Over the past six months, we’ve made a start on mapping out our preservation risk at The National Archives, working with statisticians at Warwick University to model our digital preservation processes and the threats to our collections. So far, so good – it’s looking really promising – but what we really need now is much more hard data. Like many institutions, we have a fair amount of experience as digital archivists but we don’t have a long history of measuring things. Finding the evidence to plug into the model is difficult for us, or for any individual institution.
As far as we know, the evidence base to support this quantitative approach doesn’t exist anywhere in a form we can use today. But it does exist in the wealth of knowledge, experience and data that is spread across the digital preservation community. That’s why we need your help. We’re keen to understand what kinds of things it’s possible to measure, and how far data collected in one preservation environment can help us understand another. This covers everything from how many different file formats we have, or how often disk drives fail, to harder questions around investing in our people or the complexity of our environments.
Your knowledge could help create a more systematic approach to risk management that would help us all make better informed, better evidenced decisions. So, whether you’ve built your own risk model or framework, would like to work with us, could help critically evaluate the work we’ve done, or if you have data to share, please do get in touch. We’d very much like to hear from you.