








































































































































Hannah Merwood is a Research Assistant in the Digital Archiving department at The National Archives.
Last year Sonia Ranade and Alec Mulinder wrote a blog introducing the work we are doing at The National Archives to create a new method to manage digital preservation risk. In January, our lottery funded research project “Safeguarding the Nation’s Digital Memory'' was launched - a collaborative project with statisticians at the University of Warwick and other UK archive partners to develop a risk management decision-support tool based on data and evidence.
We have been making great progress towards developing both the back-end of the model and the graphical user interface and are looking forward to sharing our work more widely in the near future. Workshops to test our first prototype are now available to book on the DPC events page. For more information about our project and our events check out our webpage.
In the meantime, we’d like to tell you about one of the digital preservation risks in our network and give you a glimpse of how the model has developed.
Model terminology
Before we start, a brief guide to our terminology. Our model is a Bayesian network. This means we have a network of digital preservation risks such as loss of integrity, not having any content metadata and short storage life. These risks - mathematically referred to as nodes - are carefully linked to each other when a natural relationship between them exists, e.g. there is a relationship between a “storage medium” such as a CD or floppy disk and the risk of “obsolescence”. Each node will also have associated probabilities of that risk occurring.
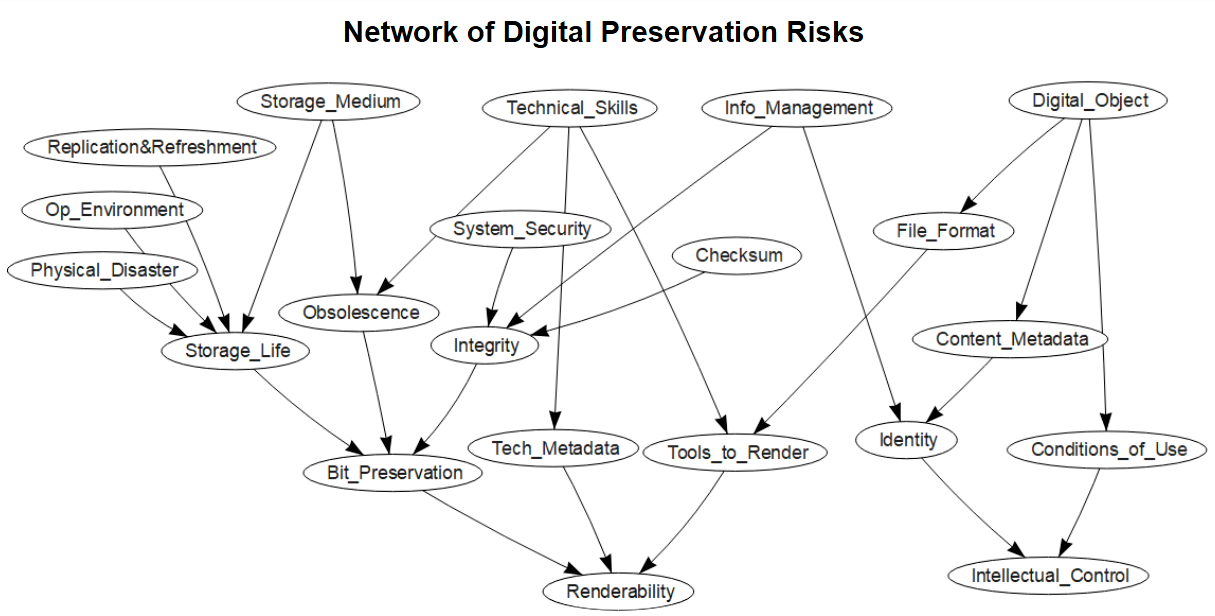
Ultimately, the tool will score an archives’ risk-management strategy based on the proportion of files which are renderable and where the archive has full intellectual control. These two outcomes can be calculated based on the probabilities of all the other risk events in the network, provided everything is carefully and accurately defined.
So, introducing technical metadata...
 Why is technical metadata in the model?
Why is technical metadata in the model?
At first, we had one node called ‘metadata’ to represent the need for documentation of both the content and technical information on a file in order to digitally preserve it. However, we then realised that we needed to make a distinction between these two types of metadata as they affect different digital preservation outcomes - descriptive and administrative metadata is needed to have full intellectual control, whereas insufficient technical metadata could hinder the renderability of a file.
As technical metadata is a characteristic that doesn’t have a comparable equivalent in the analogue world, we were also keen to highlight its significance, as this risk may be new even to many experienced archivists.
What precisely is the risk here?
To answer this, we need to look into the semantics of the definition of technical metadata. For our risk model, the definition is as follows:
“Technical information that describes how a file functions and that enables a computer to understand it at the bit level, so that it can be rendered in a way that is faithful to its original content.” Adapted from: Fundamentals of AV Preservation - Chapter 4
This might seem obvious but it's taken us a while to settle on something that conveys exactly what we mean.
Our first definition was broader as we tried to capture everything that the usual concept of analogue archival metadata would not cover... "Includes technical information that applies to any file type, such as information about the software and hardware on which the digital object can be rendered or executed, or checksums and digital signatures to ensure fixity and authenticity." From the Digital Preservation Metadata Standards.pdf.
 However, as the model evolved we realised we were actually trying to merge three separate risks into one:
However, as the model evolved we realised we were actually trying to merge three separate risks into one:
-
Having fixity information to know whether the file has changed.
-
Having the information to know which tools can render the file.
-
Having the information to know how the file should be rendered.
-
The first relates to the risk of preserving integrity, so we have created a separate digital preservation risk around whether or not a checksum was received with the file or was generated instantly on deposit by the archive. This is an important risk in digital preservation in order to protect a record from human and cyber manipulation, whether accidental or deliberate.
The difference between 2 and 3 is a bit more subtle.
In our day-to-day lives we will render lots of files of different formats on various devices without consciously thinking about the file extension or which software to use - in fact, most of the time our operating system will decide how to open something for us. This is where the second risk comes in; not having the tools to render the file, which tends to occur if your file type is rare and proprietary and you don’t have the digital preservation skills to find a work around (such as software emulation or file migration). With rapidly evolving technology, digital archivists will be facing new challenges to try and combat these threats of file format and software obsolescence. Furthermore, access to tools will always depend upon IT - even if you have the skills and the knowledge, equipment capabilities or IT policies might still create barriers.
Provided you have the digital object and the necessary software installed, it can be  rendered. However, how do we know that we are seeing the object how it was originally meant to be seen? Outside of archival contexts this is something we don’t often consider; if the file opens, we are happy. But if we are responsible for digitally preserving an object then this isn’t enough. We need to know whether a video is missing audio streams, a picture is missing a colour, or an email is missing attachments. We might be able to judge this if the depositor provided detailed information on the technical specification, but this would require a very organised and conscientious depositor! Instead, we most likely have to work this out for ourselves by extracting and analysing this information, which requires specialist skills and tools. Not having this information is the risk we now refer to when we talk about technical metadata.
rendered. However, how do we know that we are seeing the object how it was originally meant to be seen? Outside of archival contexts this is something we don’t often consider; if the file opens, we are happy. But if we are responsible for digitally preserving an object then this isn’t enough. We need to know whether a video is missing audio streams, a picture is missing a colour, or an email is missing attachments. We might be able to judge this if the depositor provided detailed information on the technical specification, but this would require a very organised and conscientious depositor! Instead, we most likely have to work this out for ourselves by extracting and analysing this information, which requires specialist skills and tools. Not having this information is the risk we now refer to when we talk about technical metadata.
How will we measure it?
 This project is all about numbers. For each node in our network, there is an associated question whose answer is used to update the model and recalculate the overall risk.
This project is all about numbers. For each node in our network, there is an associated question whose answer is used to update the model and recalculate the overall risk.
You can never fully recreate the conditions under which the record was originally intended for use, but as archivists we can try our best to explain the context and replicate the digital environment. Having an identity report generated from a tool such as DROID (a file format identification tool) and running further validation tools on more complex files such as jpylyzer for JPEG2000 or veraPDF for PDF-A, should be enough to enable the archivist to know what a faithful render of the file will be at a basic level. However, we also want to acknowledge that this is dependent on an archive staff's technical knowledge, so will therefore allow the probability of having complete technical metadata to vary based on how ‘good’ the archive staff’s digital preservation skills are too.
So, the question that we will use to estimate the proportion of objects at risk due to incomplete technical metadata is as follows:
“Conditional on the level of technical skills within your archive, what proportion of your files have sufficient technical metadata?”
This question is something for which we do not have data, so we have aggregated judgements on this from a range of digital archiving experts instead. This question was one of many that was elicited as part of a two day virtual workshop held last month, where we followed structured elicitation protocol to help guard against biases that commonly occur when asking individuals for probabilities. This way we hope to derive a fair probability for having complete technical metadata that reflects the situation across UK digital archives.
We hope that this discussion around technical metadata has given you a flavour of what this project will cover. For more information about our project check out our webpage or sign up to one of our online workshops on 16th June or 17th July.